
Tác giả: Leopold Aschenbrenner, Tháng 6 năm 2024
Tác giả: Leopold Aschenbrenner, Tháng 6 năm 2024
Bạn có thể thấy tương lai sớm nhất tại San Francisco.
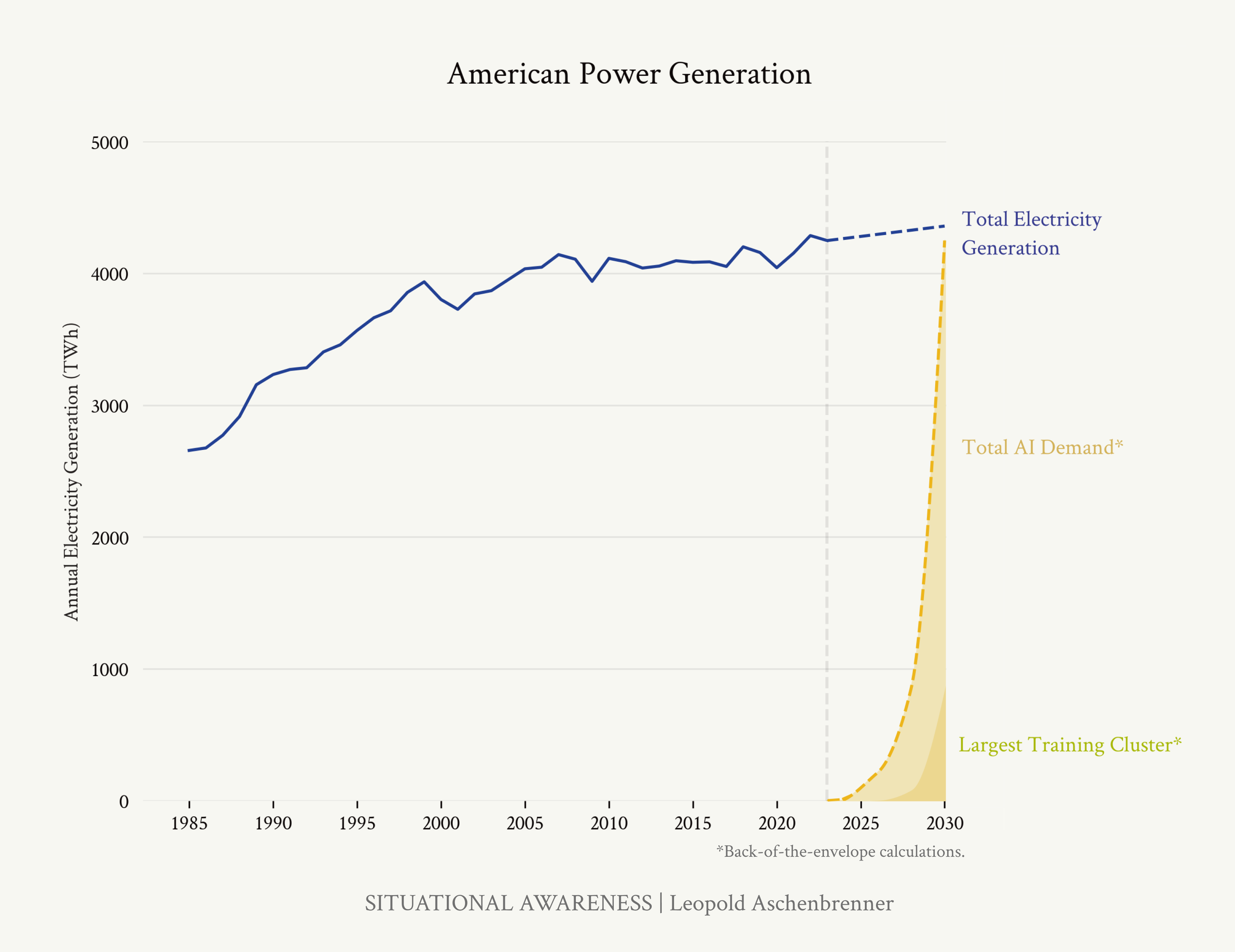
Trong năm qua, các cuộc thảo luận tại đây đã chuyển dịch từ các cụm máy chủ trị giá 10 tỷ đô la sang 100 tỷ đô la, rồi đến những cụm máy chủ nghìn tỷ đô la. Cứ mỗi sáu tháng, một số không lại được thêm vào các kế hoạch của ban quản trị. Đằng sau hậu trường là một cuộc tranh giành khốc liệt để đảm bảo mọi hợp đồng điện năng còn trống cho đến cuối thập kỷ, mọi máy biến áp có thể mua được. Các doanh nghiệp lớn của Mỹ đang chuẩn bị đổ hàng nghìn tỷ đô la vào một cuộc huy động sức mạnh công nghiệp chưa từng thấy trong nhiều thập kỷ qua. Đến cuối thập kỷ này, sản lượng điện của Mỹ sẽ tăng trưởng hàng chục phần trăm; từ những cánh đồng đá phiến ở Pennsylvania đến những trang trại điện mặt trời ở Nevada, hàng trăm triệu GPU sẽ hoạt động không ngừng nghỉ.
Cuộc đua AGI đã bắt đầu. Chúng ta đang chế tạo những cỗ máy có khả năng suy nghĩ và lập luận. Đến năm 2025/26, những cỗ máy này sẽ vượt xa nhiều sinh viên tốt nghiệp đại học. Đến cuối thập kỷ, chúng sẽ thông minh hơn bạn hoặc tôi; chúng ta sẽ có siêu trí tuệ, theo đúng nghĩa đen của từ này. Trên hành trình đó, các lực lượng an ninh quốc gia chưa từng thấy trong nửa thế kỷ qua sẽ được huy động, và chẳng bao lâu nữa, "Dự án" (The Project) sẽ bắt đầu. Nếu may mắn, chúng ta sẽ ở trong một cuộc đua tổng lực với ĐCSTQ; nếu không may, đó sẽ là một cuộc chiến tổng lực.
Mọi người hiện đều đang nói về AI, nhưng ít ai có được dù chỉ là một tia nhận thức mờ nhạt về những gì sắp ập đến. Các nhà phân tích của Nvidia vẫn nghĩ rằng năm 2024 có thể đã gần đến đỉnh điểm. Những học giả chính thống vẫn kẹt trong sự mù quáng cố hữu rằng "đó chỉ là dự đoán từ tiếp theo". Họ chỉ thấy sự cường điệu và các hoạt động kinh doanh thông thường; cùng lắm họ coi đó là một sự thay đổi công nghệ ở quy mô internet.
Chẳng bao lâu nữa, thế giới sẽ thức tỉnh. Nhưng ngay lúc này, có lẽ chỉ có vài trăm người, hầu hết ở San Francisco và các phòng thí nghiệm AI, là có nhận thức tình huống. Thông qua bất kỳ sự sắp đặt kỳ lạ nào của số phận, tôi đã thấy mình nằm trong số họ. Vài năm trước, những người này bị chế giễu là điên rồ—nhưng họ tin vào các đường xu hướng, điều đã cho phép họ dự đoán chính xác những tiến bộ của AI trong vài năm qua. Liệu những người này có đúng về vài năm tới hay không vẫn còn phải chờ xem. Nhưng đây là những người rất thông minh—những người thông minh nhất mà tôi từng gặp—và họ chính là những người đang xây dựng công nghệ này. Có lẽ họ sẽ là một chú thích kỳ quặc trong lịch sử, hoặc có lẽ họ sẽ đi vào lịch sử như Szilard, Oppenheimer và Teller. Nếu họ nhìn thấy tương lai chính xác dù chỉ là một phần, chúng ta sắp bước vào một hành trình đầy biến động.
Hãy để tôi kể cho bạn nghe những gì chúng tôi thấy.
Việc đạt được AGI vào năm 2027 là một kịch bản cực kỳ khả thi. Từ GPT-2 đến GPT-4, chúng ta đã đi từ khả năng của một ~đứa trẻ mẫu giáo đến ~học sinh trung học thông minh chỉ trong vòng 4 năm. Lần theo các đường xu hướng về năng lực tính toán (~0,5 bậc quy mô hay OOMs mỗi năm), hiệu quả thuật toán (~0,5 OOMs mỗi năm) và những bước tiến từ việc "giải phóng tiềm năng" (unhobbling - từ chatbot thành tác nhân tự hành), chúng ta hoàn toàn có thể mong đợi một bước nhảy vọt tương tự từ cấp độ mẫu giáo lên trung học vào năm 2027.
Trong bài này:
* Bốn năm qua
* Từ GPT-2 đến GPT-4
* Các xu hướng trong Deep Learning (Học sâu)
* Đếm các OOMs
* Compute (Năng lực tính toán)
* Hiệu quả thuật toán
* Rào cản dữ liệu
* Giải phóng tiềm năng (Unhobbling)
* Từ chatbot đến tác nhân đồng nghiệp (Agent-coworker)
* Bốn năm tới
* Phụ lục: Cuộc đua qua các OOMs: Thập kỷ này hoặc không bao giờ
Hãy nhìn xem. Các mô hình, chúng chỉ muốn học thôi. Bạn phải hiểu điều này. Các mô hình, chúng chỉ muốn học.
Ilya Sutskever (khoảng năm 2015, qua lời Dario Amodei)
Khả năng của GPT-4 đã gây sốc cho nhiều người: một hệ thống AI có thể viết mã và tiểu luận, có thể suy luận qua các bài toán khó và đạt điểm cao trong các kỳ thi đại học. Vài năm trước, hầu hết mọi người đều nghĩ đây là những bức tường không thể xuyên phá.
Nhưng GPT-4 chỉ đơn thuần là sự tiếp nối của một thập kỷ tiến bộ chóng mặt trong lĩnh vực học sâu (deep learning). Một thập kỷ trước, các mô hình còn khó khăn trong việc nhận diện những hình ảnh đơn giản về chó và mèo; bốn năm trước, GPT-2 còn chưa thể xâu chuỗi được những câu văn bán-hợp-lý. Giờ đây, chúng ta đang nhanh chóng đạt đến giới hạn của tất cả các bài kiểm tra đánh giá (benchmarks) mà chúng ta có thể nghĩ ra. Tuy nhiên, sự tiến bộ ngoạn mục này chỉ đơn giản là kết quả của các xu hướng nhất quán trong việc mở rộng quy mô (scaling up) học sâu.
Đã có những người nhìn thấy điều này từ lâu. Họ từng bị chế giễu, nhưng tất cả những gì họ làm là tin vào các đường xu hướng. Các đường xu hướng này rất mãnh liệt, và họ đã đúng. Các mô hình, chúng chỉ muốn học; bạn mở rộng quy mô của chúng, và chúng học được nhiều hơn.
Tôi đưa ra khẳng định sau: cực kỳ khả thi rằng đến năm 2027, các mô hình sẽ có khả năng làm công việc của một nhà nghiên cứu hoặc kỹ sư AI. Điều đó không đòi hỏi phải tin vào khoa học viễn tưởng; nó chỉ đòi hỏi việc tin vào những đường thẳng trên biểu đồ.
Trong bài viết này, tôi sẽ đơn giản là "đếm các OOMs" (OOM = Order of Magnitude - bậc quy mô, 10x = 1 OOM): xem xét các xu hướng về 1) compute (năng lực tính toán), 2) hiệu quả thuật toán (những tiến bộ thuật toán mà chúng ta có thể coi là làm tăng "năng lực tính toán hiệu dụng"), và 3) các bước tiến từ "giải phóng tiềm năng" (unhobbling - khắc phục những hạn chế rõ ràng khiến các mô hình bị kìm hãm mặc định, giải phóng các khả năng tiềm ẩn và cung cấp công cụ cho chúng, dẫn đến những bước nhảy vọt về tính hữu dụng). Chúng ta theo dõi sự tăng trưởng của mỗi yếu tố trong bốn năm trước GPT-4, và những gì chúng ta nên kỳ vọng trong bốn năm sau đó, cho đến cuối năm 2027. Với những cải tiến nhất quán của học sâu cho mỗi OOM năng lực tính toán hiệu dụng, chúng ta có thể sử dụng điều này để dự phóng tiến trình tương lai.
Công khai mà nói, mọi thứ có vẻ im ắng trong một năm kể từ khi GPT-4 ra mắt, vì thế hệ mô hình tiếp theo đang được "nướng trong lò" — khiến một số người tuyên bố về sự trì trệ và rằng học sâu đang chạm tường. Nhưng bằng cách đếm các OOMs, chúng ta có thể hé nhìn thấy những gì thực sự nên kỳ vọng.
Kết luận khá đơn giản. Từ GPT-2 đến GPT-4 — từ những mô hình gây ấn tượng vì đôi khi xâu chuỗi được vài câu mạch lạc, đến những mô hình vượt qua các kỳ thi trung học — không phải là một thành tựu chỉ có một lần. Chúng ta đang chạy đua qua các OOMs cực kỳ nhanh chóng, và các con số chỉ ra rằng chúng ta nên kỳ vọng một đợt mở rộng quy mô năng lực tính toán hiệu dụng thêm ~100.000 lần nữa — dẫn đến một bước nhảy vọt định tính khác có quy mô tương đương từ GPT-2 lên GPT-4 — trong vòng bốn năm tới. Hơn nữa, và điều này rất quan trọng, điều đó không chỉ có nghĩa là một chatbot tốt hơn; việc khai thác những "thành quả treo thấp" (low-hanging fruit) từ việc "giải phóng tiềm năng" sẽ đưa chúng ta từ chatbot đến các tác nhân tự hành (agents), từ một công cụ trở thành một thứ gì đó giống như sự thay thế trực tiếp cho nhân viên làm việc từ xa.
Mặc dù suy luận này đơn giản, nhưng hệ quả của nó thật kinh ngạc. Một bước nhảy vọt khác như vậy rất có thể đưa chúng ta đến AGI, đến những mô hình thông minh như các Tiến sĩ hoặc chuyên gia có thể làm việc bên cạnh chúng ta như những đồng nghiệp. Có lẽ quan trọng nhất là, nếu các hệ thống AI này có thể tự động hóa chính việc nghiên cứu AI, điều đó sẽ khởi động các vòng phản hồi mãnh liệt — chủ đề của bài viết tiếp theo trong loạt bài này.
Ngay cả bây giờ, hầu như không ai tính đến tất cả những điều này. Nhưng nhận thức tình huống về AI thực tế không khó đến thế, một khi bạn lùi lại và nhìn vào các xu hướng. Nếu bạn liên tục bị ngạc nhiên bởi các khả năng của AI, hãy bắt đầu đếm các OOMs.
Giờ đây, chúng ta đã có những cỗ máy mà về cơ bản chúng ta có thể trò chuyện như với con người. Đó là một minh chứng đáng chú ý cho khả năng thích nghi của con người khi điều này dường như trở nên bình thường, rằng chúng ta đã trở nên quen thuộc với tốc độ tiến bộ này. Nhưng điều đáng làm là lùi lại và nhìn vào tiến trình chỉ trong vài năm qua.
Hãy để tôi nhắc bạn về quãng đường chúng ta đã đi được chỉ trong khoảng 4 năm (!) dẫn tới GPT-4.
GPT-2 (2019) ~ Trẻ mẫu giáo: "Wow, nó có thể xâu chuỗi được vài câu hợp lý." Một ví dụ được chọn lọc kỹ lưỡng về một câu chuyện bán mạch lạc về những con kỳ lân ở dãy Andes mà nó tạo ra đã cực kỳ ấn tượng vào thời điểm đó. Tuy nhiên, GPT-2 khó có thể đếm đến 5 mà không bị vấp; khi tóm tắt một bài báo, nó chỉ nhỉnh hơn một chút so với việc chọn ngẫu nhiên 3 câu từ bài báo đó.

Việc so sánh khả năng của AI với trí tuệ con người là khó khăn và có nhiều thiếu sót, nhưng tôi nghĩ sẽ có ích khi xem xét sự tương tự ở đây. GPT-2 gây sốc vì khả năng làm chủ ngôn ngữ, và khả năng thỉnh thoảng tạo ra một đoạn văn bán mạch lạc, hoặc đôi khi trả lời đúng các câu hỏi thực tế đơn giản. Đó là những gì sẽ gây ấn tượng đối với một đứa trẻ mẫu giáo.
GPT-3 (2020) ~ Học sinh tiểu học: "Wow, chỉ với vài ví dụ (few-shot), nó có thể thực hiện một số tác vụ hữu ích đơn giản." Nó bắt đầu trở nên mạch lạc ngay cả trên nhiều đoạn văn một cách nhất quán hơn nhiều, và có thể sửa lỗi ngữ pháp cũng như thực hiện một số phép tính số học cơ bản. Lần đầu tiên, nó cũng có ích về mặt thương mại trong một vài cách hẹp: ví dụ, GPT-3 có thể tạo ra các đoạn văn đơn giản cho SEO và marketing.

Một lần nữa, sự so sánh này là không hoàn hảo, nhưng điều gây ấn tượng với mọi người về GPT-3 có lẽ là những gì sẽ gây ấn tượng đối với một học sinh tiểu học: nó viết được một số bài thơ cơ bản, có thể kể những câu chuyện phong phú và mạch lạc hơn, có thể bắt đầu lập trình sơ đẳng, có thể học hỏi khá tin cậy từ các hướng dẫn và trình diễn đơn giản, v.v.
GPT-4 (2023) ~ Học sinh trung học thông minh: "Wow, nó có thể viết mã khá phức tạp và gỡ lỗi lặp đi lặp lại, nó có thể viết một cách thông minh và tinh tế về các chủ đề phức tạp, nó có thể suy luận qua các bài toán thi đấu trung học khó, nó đang đánh bại đại đa số học sinh trung học trong bất kỳ bài kiểm tra nào chúng ta đưa ra, v.v." Từ mã nguồn đến toán học hay các ước tính Fermi, nó có thể suy nghĩ và suy luận. GPT-4 hiện hữu ích trong các công việc hàng ngày của tôi, từ việc giúp viết mã đến chỉnh sửa các bản nháp.

Trong mọi thứ từ các kỳ thi AP đến SAT, GPT-4 đạt điểm cao hơn đại đa số học sinh trung học.

Tất nhiên, ngay cả GPT-4 vẫn còn đôi chỗ chưa đồng đều; đối với một số tác vụ, nó tốt hơn nhiều so với học sinh trung học thông minh, trong khi có những tác vụ khác nó vẫn chưa làm được. Nói vậy, tôi có xu hướng nghĩ rằng hầu hết các hạn chế này bắt nguồn từ những cách hiển nhiên mà các mô hình vẫn đang bị kìm hãm (hobbled), như tôi sẽ thảo luận kỹ hơn sau. Trí tuệ thô (raw intelligence) hầu như đã có ở đó, ngay cả khi các mô hình vẫn bị hạn chế một cách nhân tạo; sẽ cần thêm công việc để giải phóng khả năng của các mô hình trong việc áp dụng hoàn toàn trí tuệ thô đó trên các ứng dụng.
Tiến bộ chỉ trong bốn năm. Bạn đang ở đâu trên đường thẳng này?
Tốc độ tiến bộ của học sâu trong thập kỷ qua đơn giản là phi thường. Chỉ một thập kỷ trước, việc một hệ thống học sâu nhận diện được những hình ảnh đơn giản đã là một cuộc cách mạng. Ngày nay, chúng ta liên tục cố gắng nghĩ ra những bài kiểm tra mới, khó hơn bao giờ hết, vậy mà mỗi benchmark mới đều nhanh chóng bị phá vỡ. Trước đây phải mất hàng thập kỷ để giải quyết các benchmark được sử dụng rộng rãi; giờ đây cảm giác như chỉ mất vài tháng.

Chúng ta thực sự đang cạn kiệt các benchmark. Như một giai thoại, những người bạn của tôi là Dan và Collin đã tạo ra một benchmark mang tên MMLU vài năm trước, vào năm 2020. Họ hy vọng cuối cùng sẽ tạo ra một benchmark đứng vững trước thử thách của thời gian, tương đương với tất cả các kỳ thi khó nhất mà chúng ta dành cho học sinh trung học và sinh viên đại học. Chỉ ba năm sau, nó cơ bản đã được giải quyết: các mô hình như GPT-4 và Gemini đạt được ~90%.
Nói rộng hơn, GPT-4 hầu như giải quyết được tất cả các bài kiểm tra năng lực trung học và đại học tiêu chuẩn. (Và ngay cả bước nhảy một năm từ GPT-3.5 lên GPT-4 thường đưa chúng ta từ mức dưới trung bình của con người lên mức đứng đầu trong phạm vi của con người.)

Hoặc hãy xem xét benchmark MATH, một tập hợp các bài toán khó từ các cuộc thi toán trung học. Khi benchmark này được công bố vào năm 2021, các mô hình tốt nhất chỉ giải đúng được ~5% số bài toán. Và bài báo gốc đã lưu ý rằng: "Hơn nữa, chúng tôi nhận thấy rằng việc đơn giản là tăng ngân sách và số lượng tham số mô hình sẽ là không thực tế để đạt được khả năng suy luận toán học mạnh mẽ nếu các xu hướng mở rộng quy mô tiếp tục [...]. Để có thêm lực đẩy trong việc giải quyết các bài toán, chúng ta có thể sẽ cần những tiến bộ thuật toán mới từ cộng đồng nghiên cứu rộng lớn hơn" — chúng ta sẽ cần những đột phá mới căn bản để giải quyết MATH, hoặc họ đã nghĩ như vậy. Một cuộc khảo sát các nhà nghiên cứu ML dự đoán tiến bộ tối thiểu trong những năm tới; vậy mà chỉ trong vòng một năm (đến giữa năm 2022), các mô hình tốt nhất đã đi từ ~5% lên 50% độ chính xác; giờ đây, MATH cơ bản đã được giải quyết, với hiệu suất gần đây đạt trên 90%.

Hết lần này đến lần khác, năm này qua năm khác, những người hoài nghi đã tuyên bố "học sâu sẽ không thể làm được X" và đã nhanh chóng bị chứng minh là sai. Nếu có một bài học mà chúng ta rút ra được từ thập kỷ qua của AI, thì đó là bạn không bao giờ nên đặt cược chống lại học sâu.
Giờ đây, các benchmark khó nhất chưa được giải quyết là các bài kiểm tra như GPQA, một tập hợp các câu hỏi cấp độ Tiến sĩ về sinh học, hóa học và vật lý. Nhiều câu hỏi đọc lên nghe như những từ ngữ vô nghĩa đối với tôi, và ngay cả những Tiến sĩ trong các lĩnh vực khoa học khác dành hơn 30 phút tra cứu Google cũng khó có thể đạt điểm cao hơn mức xác suất ngẫu nhiên. Claude 3 Opus hiện đạt ~60%, so với các Tiến sĩ đúng chuyên ngành đạt ~80% — và tôi kỳ vọng benchmark này cũng sẽ bị chinh phục trong một hoặc hai thế hệ tới.

Làm thế nào điều này đã xảy ra? Phép màu của học sâu là nó "chỉ việc hoạt động" — và các đường xu hướng đã nhất quán một cách đáng kinh ngạc, bất chấp những người phản đối ở mọi ngã rẽ.
Với mỗi OOM năng lực tính toán hiệu dụng, các mô hình sẽ trở nên tốt hơn một cách có thể dự đoán và tin cậy. Nếu chúng ta có thể đếm các OOMs, chúng ta có thể (một cách đại khái, về mặt định tính) ngoại suy những cải thiện về năng lực. Đó là cách mà một vài cá nhân có tầm nhìn xa đã thấy trước sự ra đời của GPT-4.

Chúng ta có thể phân rã tiến trình trong bốn năm từ GPT-2 đến GPT-4 thành ba hạng mục mở rộng quy mô (scaleups):
Chúng ta có thể "đếm các OOMs" cải tiến dọc theo các trục này: tức là theo dõi quy mô tăng trưởng của mỗi yếu tố theo đơn vị năng lực tính toán hiệu dụng. 3x là 0,5 OOMs; 10x là 1 OOM; 30x là 1,5 OOMs; 100x là 2 OOMs; và vân vân. Chúng ta cũng có thể xem xét những gì nên kỳ vọng trên nền tảng GPT-4, từ năm 2023 đến 2027.
Tôi sẽ đi qua từng cái một, nhưng kết luận là rõ ràng: chúng ta đang chạy đua qua các OOMs một cách nhanh chóng. Có những trở ngại tiềm tàng từ rào cản dữ liệu, điều mà tôi sẽ đề cập — nhưng nhìn chung, có khả năng cao là chúng ta nên kỳ vọng một bước nhảy vọt khác tương đương từ GPT-2 lên GPT-4, chồng lên trên GPT-4, vào năm 2027.
Tôi sẽ bắt đầu với động lực được thảo luận phổ biến nhất của tiến bộ gần đây: đổ (rất) nhiều năng lực tính toán hơn vào các mô hình.
Nhiều người cho rằng điều này đơn giản là do Định luật Moore. Nhưng ngay cả trong thời kỳ hoàng kim của Định luật Moore, nó vẫn diễn ra tương đối chậm chạp — có lẽ là 1-1,5 OOMs mỗi thập kỷ. Thay vào đó, chúng ta đang thấy những đợt mở rộng quy mô năng lực tính toán nhanh hơn nhiều — gần gấp 5 lần tốc độ của Định luật Moore — vì sự đầu tư khổng lồ. (Việc chi tiêu dù chỉ một triệu đô la cho một mô hình duy nhất từng là một ý tưởng điên rồ mà không ai thèm quan tâm, còn giờ đây đó chỉ là tiền lẻ!)
Chúng ta có thể sử dụng các ước tính công khai từ Epoch AI (một nguồn được tôn trọng rộng rãi nhờ những phân tích xuất sắc về các xu hướng AI) để theo dõi đợt mở rộng quy mô năng lực tính toán từ năm 2019 đến 2023. Từ GPT-2 sang GPT-3 là một đợt mở rộng nhanh chóng; có một lượng "năng lực tính toán dư thừa" lớn, mở rộng từ một thử nghiệm nhỏ đến việc sử dụng toàn bộ một trung tâm dữ liệu để huấn luyện một mô hình ngôn ngữ lớn. Với đợt mở rộng từ GPT-3 sang GPT-4, chúng ta đã chuyển sang chế độ hiện đại: phải xây dựng một cụm máy chủ hoàn toàn mới (lớn hơn nhiều) cho mô hình tiếp theo. Tuy nhiên, sự tăng trưởng ngoạn mục vẫn tiếp tục. Nhìn chung, các ước tính của Epoch AI cho thấy việc huấn luyện GPT-4 đã sử dụng năng lực tính toán thô nhiều hơn ~3.000x-10.000x so với GPT-2.

Về bản chất, đây chỉ là sự tiếp nối của một xu hướng dài hạn hơn. Trong một thập kỷ rưỡi qua, chủ yếu là do sự mở rộng quy mô đầu tư trên diện rộng (và việc chuyên biệt hóa các chip cho khối lượng công việc AI dưới dạng GPU và TPU), năng lực tính toán huấn luyện được sử dụng cho các hệ thống AI tiên phong đã tăng trưởng ở mức khoảng ~0,5 OOMs/năm.
Đợt mở rộng năng lực tính toán từ GPT-2 sang GPT-3 trong một năm là một sự dư thừa bất thường, nhưng tất cả các dấu hiệu đều cho thấy xu hướng dài hạn sẽ tiếp tục. "Thế giới tin đồn" ở San Francisco đang xôn xao với những câu chuyện đầy kịch tính về các đơn đặt hàng GPU khổng lồ. Các khoản đầu tư liên quan sẽ là phi thường — nhưng chúng đang được thực hiện. Tôi sẽ đi sâu hơn vào vấn đề này sau trong loạt bài, ở phần IIIa. Cuộc đua tới Cụm máy chủ nghìn tỷ đô la; dựa trên phân tích đó, việc tăng thêm 2 OOMs năng lực tính toán (một cụm máy chủ trị giá hàng chục tỷ đô la) dường như rất chắc chắn sẽ xảy ra vào cuối năm 2027; thậm chí một cụm máy chủ gần mức +3 OOMs năng lực tính toán (hơn 100 tỷ đô la) dường như cũng khả thi (và có tin đồn đang được Microsoft/OpenAI triển khai).
Trong khi các khoản đầu tư khổng lồ vào năng lực tính toán thu hút mọi sự chú ý, tiến bộ thuật toán có lẽ là một động lực quan trọng tương đương cho tiến trình (và đã bị đánh giá thấp một cách đáng kể).
Để thấy tiến bộ thuật toán có thể có tầm ảnh hưởng lớn như thế nào, hãy xem xét minh họa sau về sự sụt giảm chi phí để đạt được độ chính xác ~50% trên benchmark MATH (toán thi đấu trung học) chỉ trong vòng hai năm. (Để so sánh, một nghiên cứu sinh Tiến sĩ khoa học máy tính không đặc biệt thích toán đạt 40%, vì vậy kết quả này đã là rất tốt.) Hiệu quả suy luận (inference efficiency) đã cải thiện gần 3 OOMs — gấp 1.000 lần — trong vòng chưa đầy hai năm.

Mặc dù đây chỉ là những con số cho hiệu quả suy luận (có thể hoặc không tương ứng với những cải thiện hiệu quả huấn luyện, nơi các con số khó suy luận hơn từ dữ liệu công khai), chúng làm rõ rằng có một lượng tiến bộ thuật toán khổng lồ khả thi và đang diễn ra.
Trong bài này, tôi sẽ tách biệt hai loại tiến bộ thuật toán. Ở đây, tôi sẽ bắt đầu bằng việc đề cập đến các cải tiến thuật toán "trong-hệ-hình" (within-paradigm) — những cải tiến đơn giản dẫn đến các mô hình nền tảng tốt hơn, và hoạt động trực tiếp như các hiệu quả năng lực tính toán hoặc hệ số nhân năng lực tính toán. Ví dụ, một thuật toán tốt hơn có thể cho phép chúng ta đạt được cùng một hiệu suất nhưng với năng lực tính toán huấn luyện ít hơn 10 lần. Ngược lại, điều đó sẽ đóng vai trò như việc tăng 10x (1 OOM) năng lực tính toán hiệu dụng. (Sau đó, tôi sẽ đề cập đến "giải phóng tiềm năng" (unhobbling), thứ mà bạn có thể coi là tiến bộ thuật toán "mở rộng hệ hình/mở rộng ứng dụng" giúp giải phóng các khả năng của các mô hình nền tảng.)
Nếu chúng ta lùi lại và nhìn vào các xu hướng dài hạn, chúng ta dường như tìm thấy các cải tiến thuật toán mới ở một tốc độ khá nhất quán. Các khám phá riêng lẻ có vẻ ngẫu nhiên, và ở mọi ngã rẽ, dường như đều có những trở ngại không thể vượt qua — nhưng đường xu hướng dài hạn là có thể dự đoán được, một đường thẳng trên biểu đồ. Hãy tin vào đường xu hướng.
Chúng ta có dữ liệu tốt nhất cho ImageNet (nơi nghiên cứu thuật toán chủ yếu là công khai và chúng ta có dữ liệu kéo dài một thập kỷ), theo đó chúng ta đã liên tục cải thiện hiệu quả năng lực tính toán khoảng ~0,5 OOMs/năm trong giai đoạn 9 năm từ 2012 đến 2021.

Đó là một vấn đề lớn: điều đó có nghĩa là 4 năm sau, chúng ta có thể đạt được cùng một hiệu suất với năng lực tính toán ít hơn ~100 lần (và đồng thời, hiệu suất cao hơn nhiều cho cùng một năng lực tính toán!).
Thật không may, vì các phòng thí nghiệm không công bố dữ liệu nội bộ về vấn đề này, nên khó có thể đo lường tiến bộ thuật toán cho các mô hình ngôn ngữ lớn (LLMs) tiên phong trong bốn năm qua. EpochAI có công trình mới lặp lại các kết quả của họ trên ImageNet cho mô hình hóa ngôn ngữ, và ước tính xu hướng hiệu quả thuật toán ~0,5 OOMs/năm tương tự trong các LLMs từ năm 2012 đến 2023. (Tuy nhiên, điều này có biên độ sai số rộng hơn và không nắm bắt được một số thành tựu gần đây hơn, vì các phòng thí nghiệm hàng đầu đã ngừng công bố các hiệu quả thuật toán của họ.)

Nhìn trực tiếp hơn vào 4 năm qua, từ GPT-2 sang GPT-3 cơ bản là một đợt mở rộng quy mô đơn giản (theo bài báo), nhưng đã có nhiều thành tựu được biết đến công khai và có thể suy luận công khai kể từ GPT-3:
Tổng hợp lại, thông tin công khai cho thấy bước nhảy vọt từ GPT-2 lên GPT-4 bao gồm 1-2 OOMs cải thiện hiệu quả thuật toán.
Trong 4 năm tiếp sau GPT-4, chúng ta nên kỳ vọng xu hướng này tiếp tục: trung bình 0,5 OOMs/năm về hiệu quả năng lực tính toán, tức là ~2 OOMs cải thiện so với GPT-4 vào năm 2027. Mặc dù các hiệu quả năng lực tính toán sẽ trở nên khó tìm hơn khi chúng ta đã khai thác hết các "thành quả treo thấp", nhưng các khoản đầu tư của các phòng thí nghiệm AI về tiền bạc và tài năng để tìm kiếm các cải tiến thuật toán mới đang tăng trưởng nhanh chóng. (Ít nhất là các hiệu quả chi phí suy luận có thể suy luận công khai dường như không hề chậm lại chút nào.) Ở mức cao, chúng ta thậm chí có thể thấy những đột phá căn bản hơn, tương tự như Transformer, với những bước tiến lớn hơn nữa.
Tổng hợp lại, điều này gợi ý rằng chúng ta nên kỳ vọng khoảng 1-3 OOMs cải thiện hiệu quả thuật toán (so với GPT-4) vào cuối năm 2027, với dự đoán khả thi nhất là khoảng ~2 OOMs.
Có một nguồn biến thiên quan trọng tiềm tàng cho tất cả những điều này: chúng ta đang cạn kiệt dữ liệu internet. Điều đó có nghĩa là, rất sớm thôi, cách tiếp cận ngây thơ là huấn luyện trước các mô hình ngôn ngữ lớn hơn trên nhiều dữ liệu thu thập được từ internet có thể bắt đầu chạm tới những điểm nghẽn nghiêm trọng.
Các mô hình tiên phong đã được huấn luyện trên phần lớn internet. Ví dụ, Llama 3 đã được huấn luyện trên hơn 15 nghìn tỷ (trillion) token. Common Crawl, một bản lưu trữ phần lớn internet được sử dụng để huấn luyện LLM, có hơn 100 nghìn tỷ token thô, mặc dù phần lớn trong số đó là thư rác và sự trùng lặp (ví dụ: một phép lọc trùng lặp tương đối đơn giản dẫn đến 30 nghìn tỷ token, ngụ ý rằng Llama 3 đã cơ bản sử dụng gần hết dữ liệu). Hơn nữa, đối với các lĩnh vực cụ thể hơn như mã nguồn, số lượng token còn ít hơn nhiều, ví dụ các kho lưu trữ github công khai được ước tính chỉ ở mức vài nghìn tỷ token.
Bạn có thể tiến xa hơn một chút bằng cách lặp lại dữ liệu, nhưng các nghiên cứu học thuật về vấn đề này cho thấy việc lặp lại chỉ đưa bạn đi xa đến một mức độ nào đó, nhận thấy rằng sau 16 kỷ nguyên (epochs - lặp lại 16 lần), lợi nhuận giảm dần cực nhanh về không. Tại một thời điểm nào đó, ngay cả khi có thêm năng lực tính toán (hiệu dụng), việc làm cho các mô hình của bạn tốt hơn có thể trở nên khó khăn hơn nhiều vì hạn chế về dữ liệu. Điều này không thể bị xem nhẹ: chúng ta đã và đang cưỡi trên các đường cong mở rộng quy mô, cưỡi trên làn sóng của hệ hình "huấn luyện trước mô hình hóa ngôn ngữ", và nếu không có thứ gì mới ở đây, hệ hình này sẽ (ít nhất là về mặt lý thuyết ngây thơ) cạn kiệt. Bất chấp những khoản đầu tư khổng lồ, chúng ta sẽ rơi vào trạng thái bão hòa. Tất cả các phòng thí nghiệm được đồn đại là đang đặt cược nghiên cứu khổng lồ vào các cải tiến thuật toán mới hoặc các cách tiếp cận để vượt qua điều này. Các nhà nghiên cứu được cho là đang thử nhiều chiến lược, từ dữ liệu tổng hợp (synthetic data) đến tự chơi (self-play) và các phương pháp học tăng cường (RL). Những người trong ngành dường như rất lạc quan: Dario Amodei (CEO của Anthropic) gần đây đã nói trong một podcast: "nếu bạn nhìn vào nó một cách rất ngây thơ, chúng ta không còn xa mức cạn kiệt dữ liệu [...] Dự đoán của tôi là đây sẽ không phải là một rào cản [...] Có rất nhiều cách khác nhau để thực hiện điều đó." Tất nhiên, bất kỳ kết quả nghiên cứu nào về vấn đề này đều là độc quyền và không được công bố trong thời gian này.
Ngoài sự lạc quan của những người trong ngành, tôi nghĩ có một lập luận cảm tính mạnh mẽ giải thích tại sao có thể tìm ra cách huấn luyện các mô hình với hiệu quả lấy mẫu (sample efficiency) tốt hơn nhiều (những cải tiến thuật toán cho phép chúng học hỏi nhiều hơn từ dữ liệu hạn chế). Hãy xem xét cách bạn hoặc tôi sẽ học từ một cuốn sách giáo khoa toán thực sự dày đặc kiến thức:
Cách thức huấn luyện các mô hình trước đây vốn đơn giản và ngây thơ, nhưng nó hoạt động hiệu quả, vì vậy không ai thực sự cố gắng hết sức để phá vỡ các phương pháp tiếp cận hiệu quả lấy mẫu này. Giờ đây khi nó có thể trở thành một hạn chế lớn hơn, chúng ta nên kỳ vọng tất cả các phòng thí nghiệm sẽ đầu tư hàng tỷ đô la và những bộ não thông minh nhất của họ để giải quyết nó. Một khuôn mẫu phổ biến trong học sâu là phải mất rất nhiều nỗ lực (và nhiều dự án thất bại) để có được các chi tiết chính xác, nhưng cuối cùng một phiên bản nào đó của những thứ rõ ràng và đơn giản sẽ hoạt động hiệu quả. Với việc học sâu đã vượt qua mọi bức tường giả định trong thập kỷ qua, dự đoán cơ bản của tôi là điều tương tự cũng sẽ xảy ra ở đây.
Hơn nữa, thực tế có vẻ khả thi là việc giải quyết một trong những ván cược thuật toán này như dữ liệu tổng hợp có thể cải thiện các mô hình một cách ngoạn mục. Đây là một trực giác: Các mô hình tiên phong hiện nay như Llama 3 được huấn luyện trên internet — và internet thì đầy rẫy những thứ rác rưởi, như thương mại điện tử hay SEO hay bất cứ thứ gì. Nhiều LLM dành đại đa số năng lực tính toán huấn luyện của chúng cho những thứ rác rưởi này, thay vì cho những dữ liệu thực sự chất lượng cao (ví dụ: các chuỗi suy luận của những người đang giải quyết các vấn đề khoa học khó). Hãy tưởng tượng nếu bạn có thể dành năng lực tính toán cấp độ GPT-4 cho hoàn toàn những dữ liệu cực kỳ chất lượng cao — nó có thể là một mô hình có khả năng hơn rất, rất nhiều.
Nhìn lại AlphaGo — hệ thống AI đầu tiên đánh bại các nhà vô địch thế giới trong trò chơi Cờ vây, nhiều thập kỷ trước khi điều đó được cho là khả thi — cũng sẽ hữu ích ở đây.
Việc phát triển bước 2 tương đương cho các LLM là một vấn đề nghiên cứu then chốt để vượt qua rào cản dữ liệu (và hơn thế nữa, cuối cùng sẽ là chìa khóa để vượt qua trí tuệ cấp độ con người).
Tất cả những điều này có nghĩa là các hạn chế về dữ liệu dường như tạo ra những biên độ sai số lớn theo cả hai hướng vào việc dự báo những năm sắp tới của tiến bộ AI. Có một khả năng thực tế là mọi thứ sẽ đình trệ (LLMs vẫn có thể có tầm ảnh hưởng lớn như internet, nhưng chúng ta sẽ không đạt tới AGI thực sự điên rồ). Nhưng tôi nghĩ thật hợp lý khi đoán rằng các phòng thí nghiệm sẽ giải quyết được nó, và việc làm đó không chỉ giữ cho các đường cong mở rộng quy mô tiếp tục, mà còn có thể cho phép những bước tiến khổng lồ về năng lực mô hình.
Bên lề một chút, điều này cũng có nghĩa là chúng ta nên kỳ vọng sự khác biệt lớn hơn giữa các phòng thí nghiệm khác nhau trong những năm tới so với hiện nay. Cho đến gần đây, các kỹ thuật tiên tiến nhất đều được công bố, vì vậy mọi người cơ bản đều làm điều tương tự. (Và các công ty mới nổi hoặc các dự án mã nguồn mở có thể dễ dàng cạnh tranh với các đơn vị tiên phong, vì công thức đã được công bố.) Giờ đây, các ý tưởng thuật toán then chốt đang ngày càng trở thành độc quyền. Tôi kỳ vọng các phương pháp tiếp cận của các phòng thí nghiệm sẽ phân kỳ nhiều hơn, và một số sẽ đạt được tiến bộ nhanh hơn những đơn vị khác — thậm chí một phòng thí nghiệm có vẻ tiên phong hiện nay có thể bị mắc kẹt tại rào cản dữ liệu trong khi những đơn vị khác đạt được đột phá cho phép họ bứt phá. Và mã nguồn mở sẽ khó cạnh tranh hơn nhiều. Điều đó chắc chắn sẽ khiến mọi thứ trở nên thú vị. (Và khi một phòng thí nghiệm giải quyết được vấn đề đó, đột phá của họ sẽ là chìa khóa tới AGI, chìa khóa tới siêu trí tuệ — một trong những bí mật quý giá nhất của Hoa Kỳ.)
Cuối cùng là hạng mục cải tiến khó định lượng nhất — nhưng không kém phần quan trọng: những gì tôi gọi là "giải phóng tiềm năng" (unhobbling).
Hãy tưởng tượng nếu khi được yêu cầu giải một bài toán khó, bạn phải trả lời ngay lập tức bằng điều đầu tiên xuất hiện trong đầu. Rõ ràng là bạn sẽ gặp khó khăn, ngoại trừ những bài toán đơn giản nhất. Nhưng cho đến gần đây, đó chính là cách chúng ta để LLMs giải các bài toán. Thay vào đó, hầu hết chúng ta giải quyết vấn đề theo từng bước trên một tờ giấy nháp, và có thể giải quyết các vấn đề khó hơn nhiều theo cách đó. "Chuỗi suy nghĩ" (Chain-of-thought - CoT) đã mở khóa điều đó cho LLMs. Bất chấp những khả năng thô xuất sắc, chúng đã kém toán hơn nhiều so với khả năng thực có vì chúng bị kìm hãm theo một cách rõ ràng, và chỉ cần một tinh chỉnh thuật toán nhỏ để giải phóng những năng lực lớn hơn nhiều.
Chúng ta đã có những bước tiến khổng lồ trong việc "giải phóng tiềm năng" của các mô hình trong vài năm qua. Đây là những cải tiến thuật toán vượt ra ngoài việc chỉ huấn luyện các mô hình nền tảng tốt hơn — và thường chỉ sử dụng một phần nhỏ năng lực tính toán huấn luyện trước — giúp khai phá năng lực của mô hình:

Một cuộc khảo sát của Epoch AI về một số kỹ thuật này, như cấu trúc hỗ trợ, sử dụng công cụ, v.v., nhận thấy rằng những kỹ thuật này thường có thể dẫn đến mức tăng năng lực tính toán hiệu dụng từ 5-30x trên nhiều benchmark. METR (một tổ chức đánh giá các mô hình) tương tự cũng tìm thấy những cải thiện hiệu suất rất lớn trên tập hợp các tác vụ tác nhân của họ, thông qua việc "giải phóng tiềm năng" từ cùng một mô hình nền tảng GPT-4: từ 5% với chỉ mô hình nền tảng, lên 20% với GPT-4 như được huấn luyện sau khi ra mắt, đến gần 40% hiện nay nhờ việc huấn luyện sau tốt hơn, các công cụ và cấu trúc hỗ trợ tác nhân.

Mặc dù khó có thể đưa những thứ này lên một thang đo năng lực tính toán hiệu dụng thống nhất với năng lực tính toán và hiệu quả thuật toán, nhưng rõ ràng đây là những bước tiến khổng lồ, ít nhất là có quy mô xấp xỉ tương đương với việc mở rộng quy mô năng lực tính toán và hiệu quả thuật toán. (Nó cũng làm nổi bật vai trò trung tâm của tiến bộ thuật toán: mức 0,5 OOMs/năm của các hiệu quả năng lực tính toán, dù đã đáng kể, mới chỉ là một phần của câu chuyện, và tổng hợp lại với các tiến bộ thuật toán giải phóng tiềm năng nói chung có lẽ chiếm đại đa số các thành tựu theo xu hướng hiện nay.)
"Giải phóng tiềm năng" (unhobbling) chính là thứ thực sự cho phép các mô hình này trở nên hữu ích — và tôi cho rằng phần lớn những gì đang kìm hãm nhiều ứng dụng thương mại hiện nay là nhu cầu về việc "giải phóng tiềm năng" thêm nữa theo hướng này. Thực tế, các mô hình ngày nay vẫn bị kìm hãm một cách khó tin! Ví dụ:
Khả năng ở đây là vô tận, và chúng ta đang nhanh chóng khai thác những "thành quả treo thấp" này. Điều này rất quan trọng: hoàn toàn sai lầm khi chỉ hình dung về "GPT-6 ChatGPT". Với tiến trình giải phóng tiềm năng liên tục, những cải thiện sẽ là những bước thay đổi đáng kể so với GPT-6 + RLHF. Đến năm 2027, thay vì một chatbot, bạn sẽ có thứ gì đó giống như một tác nhân tự hành (agent), giống như một đồng nghiệp.
Việc giải phóng tiềm năng đầy tham vọng trong những năm tới sẽ trông như thế nào? Cách tôi nghĩ về nó, có ba thành phần then chốt:
1. Giải quyết "vấn đề thích nghi" (onboarding problem)
GPT-4 có trí thông minh thô để làm một phần đáng kể công việc của nhiều người, nhưng nó giống như một nhân viên mới thông minh vừa mới xuất hiện 5 phút trước: nó không có bất kỳ ngữ cảnh liên quan nào, chưa đọc các tài liệu của công ty hay lịch sử Slack hoặc trò chuyện với các thành viên trong nhóm, hay dành thời gian để hiểu mã nguồn nội bộ của công ty. Một nhân viên mới thông minh sẽ không hữu ích lắm chỉ sau 5 phút đến nơi — nhưng họ sẽ cực kỳ hữu ích sau một tháng! Dường như có thể thực hiện được, ví dụ thông qua ngữ cảnh cực dài, việc "đưa vào làm việc" (onboarding) các mô hình giống như cách chúng ta làm với một đồng nghiệp con người mới. Chỉ riêng điều này đã là một sự giải phóng khổng lồ.
2. Sự dư thừa năng lực tính toán lúc chạy (test-time compute overhang)
Hiện tại, các mô hình cơ bản chỉ có thể thực hiện các tác vụ ngắn: bạn hỏi chúng một câu hỏi, và chúng đưa ra câu trả lời. Nhưng điều đó cực kỳ hạn chế. Hầu hết các công việc nhận thức hữu ích mà con người thực hiện đều có tầm nhìn dài hơn — nó không chỉ mất 5 phút, mà là hàng giờ, hàng ngày, hàng tuần hoặc hàng tháng.
Một nhà khoa học chỉ có thể suy nghĩ về một vấn đề khó trong 5 phút thì không thể tạo ra bất kỳ đột phá khoa học nào. Một kỹ sư phần mềm chỉ có thể viết mã khung cho một hàm duy nhất khi được yêu cầu thì sẽ không hữu ích lắm — các kỹ sư phần mềm được giao một nhiệm vụ lớn hơn, và sau đó họ đi lập kế hoạch, tìm hiểu các phần liên quan của mã nguồn hoặc các công cụ kỹ thuật, viết các mô đun khác nhau và kiểm tra chúng theo từng bước, gỡ lỗi, tìm kiếm trong không gian các giải pháp khả thi, và cuối cùng gửi một yêu cầu kéo mã lớn là kết quả của nhiều tuần làm việc. Và cứ thế.
Về bản chất, có một sự dư thừa năng lực tính toán lúc chạy (test-time compute overhang) rất lớn. Hãy coi mỗi token của GPT-4 như một từ độc thoại nội tâm khi bạn suy nghĩ về một vấn đề. Mỗi token của GPT-4 khá thông minh, nhưng hiện tại nó chỉ có thể sử dụng hiệu quả khoảng hàng trăm token cho các chuỗi suy nghĩ mạch lạc (hiệu quả giống như việc bạn chỉ có thể dành vài phút độc thoại nội tâm/suy nghĩ cho một vấn đề hoặc dự án).
Điều gì sẽ xảy ra nếu nó có thể sử dụng hàng triệu token để suy nghĩ và làm việc trên các vấn đề thực sự khó hoặc các dự án lớn hơn?
Giả sử một con người suy nghĩ ở mức ~100 token/phút và làm việc 40 giờ/tuần, việc chuyển đổi "thời gian một mô hình suy nghĩ" tính bằng token sang thời gian-người trên một vấn đề/dự án nhất định sẽ là một con số khổng lồ.
Ngay cả khi trí thông minh "trên mỗi token" là như nhau, đó sẽ là sự khác biệt giữa một người thông minh dành vài phút so với vài tháng cho một vấn đề. Tôi không biết bạn thế nào, nhưng có nhiều, nhiều, nhiều điều tôi có khả năng làm được trong vài tháng so với vài phút. Nếu chúng ta có thể mở khóa việc "có thể suy nghĩ và làm việc trên một thứ gì đó trong tương đương vài tháng, thay vì tương đương vài phút" cho các mô hình, nó sẽ mở ra một bước nhảy vọt điên rồ về năng lực. Có một sự dư thừa khổng lồ ở đây, trị giá nhiều OOMs.
Hiện tại, các mô hình chưa làm được điều này. Ngay cả với những tiến bộ gần đây trong ngữ cảnh dài, ngữ cảnh dài hơn này chủ yếu chỉ hoạt động cho việc tiêu thụ các token, chứ không phải việc tạo ra các token — sau một thời gian, mô hình sẽ đi chệch hướng hoặc bị mắc kẹt. Nó chưa thể tự mình đi giải quyết một vấn đề hoặc dự án trong một thời gian dài.
Nhưng việc giải phóng năng lực tính toán lúc chạy có thể chỉ là vấn đề của những thắng lợi thuật toán "giải phóng tiềm năng" tương đối nhỏ. Có lẽ một lượng nhỏ RL giúp mô hình học cách tự sửa lỗi ("hừm, cái đó có vẻ không đúng, để tôi kiểm tra lại"), lập kế hoạch, tìm kiếm các giải pháp khả thi, v.v. Theo một nghĩa nào đó, mô hình đã có hầu hết các khả năng thô, nó chỉ cần học thêm một vài kỹ năng bổ sung để kết hợp tất cả lại với nhau.
Về bản chất, chúng ta chỉ cần dạy cho mô hình một loại vòng lặp bên ngoài "Hệ thống II" (System II) cho phép nó suy luận thông qua các dự án dài hơi và khó khăn.
Nếu chúng ta thành công trong việc dạy vòng lặp bên ngoài này, thay vì một câu trả lời chatbot ngắn gọn vài đoạn văn, hãy tưởng tượng một dòng chảy hàng triệu từ (đến nhanh hơn mức bạn có thể đọc) khi mô hình suy nghĩ thấu đáo các vấn đề, sử dụng các công cụ, thử các phương pháp tiếp cận khác nhau, thực hiện nghiên cứu, chỉnh sửa công việc của mình, phối hợp với những người khác và tự mình hoàn thành các dự án lớn.
3. Sử dụng máy tính
Đây có lẽ là điều đơn giản nhất trong ba điều này. ChatGPT hiện tại cơ bản giống như một con người ngồi trong một chiếc hộp biệt lập mà bạn chỉ có thể nhắn tin. Trong khi các cải tiến giải phóng tiềm năng sớm dạy cho các mô hình sử dụng các công cụ biệt lập riêng lẻ, tôi kỳ vọng rằng với các mô hình đa phương thức, chúng ta sẽ sớm có thể thực hiện điều này chỉ trong một bước: chúng ta sẽ đơn giản là cho phép các mô hình sử dụng máy tính giống như một con người.
Điều đó có nghĩa là tham gia các cuộc gọi Zoom của bạn, nghiên cứu mọi thứ trực tuyến, nhắn tin và gửi email cho mọi người, đọc các tài liệu chia sẻ, sử dụng các ứng dụng và công cụ phát triển của bạn, v.v. (Tất nhiên, để các mô hình tận dụng tối đa điều này trong các vòng lặp dài hơi hơn, điều này sẽ đi đôi với việc giải phóng năng lực tính toán lúc chạy.)
Đến cuối quá trình này, tôi kỳ vọng chúng ta sẽ có được một thứ gì đó trông rất giống một nhân viên làm việc từ xa thay thế trực tiếp (drop-in remote worker). Một tác nhân tham gia vào công ty của bạn, được thích nghi như một nhân viên con người mới, nhắn tin cho bạn và đồng nghiệp trên Slack và sử dụng các phần mềm của bạn, tạo ra các yêu cầu kéo mã, và với những dự án lớn, có thể thực hiện công việc tương đương với một con người đi vắng trong vài tuần để hoàn thành dự án một cách độc lập. Bạn có thể sẽ cần các mô hình nền tảng tốt hơn một chút so với GPT-4 để mở khóa điều này, nhưng có lẽ không cần tốt hơn quá nhiều — rất nhiều tinh túy nằm ở việc khắc phục những cách thức rõ ràng và cơ bản mà các mô hình vẫn đang bị kìm hãm.
Một cái nhìn sớm về những gì điều này có thể trông như thế nào là Devin, một nguyên mẫu ban đầu của việc mở khóa "dư thừa tính tác nhân" / "dư thừa năng lực tính toán lúc chạy" trên các mô hình trên con đường tạo ra một kỹ sư phần mềm hoàn toàn tự động. Tôi không biết Devin hoạt động tốt thế nào trong thực tế, và bản demo này vẫn còn rất hạn chế so với những gì việc giải phóng tiềm năng thực sự từ chatbot -> tác nhân sẽ mang lại, nhưng nó là một đoạn giới thiệu hữu ích về những gì sắp tới.
Nhân tiện, tôi kỳ vọng tính trung tâm của việc giải phóng tiềm năng sẽ dẫn đến một hiệu ứng "tiếng nổ siêu thanh" (sonic boom) khá thú vị về mặt các ứng dụng thương mại. Các mô hình trung gian từ nay đến khi có nhân viên làm việc từ xa thay thế trực tiếp sẽ đòi hỏi rất nhiều công sức để thay đổi quy trình làm việc và xây dựng cơ sở hạ tầng để tích hợp và tạo ra giá trị kinh tế. Nhân viên làm việc từ xa thay thế trực tiếp sẽ dễ dàng tích hợp hơn đáng kể — chỉ việc đưa họ vào để tự động hóa tất cả các công việc có thể làm được từ xa. Có vẻ khả thi là công sức thay đổi quy trình sẽ mất nhiều thời gian hơn việc giải phóng tiềm năng, nghĩa là vào thời điểm nhân viên làm việc từ xa thay thế trực tiếp có thể tự động hóa một số lượng lớn công việc, các mô hình trung gian vẫn chưa được khai thác và tích hợp hoàn toàn — vì vậy bước nhảy vọt về giá trị kinh tế được tạo ra có thể sẽ không liên tục.
Tổng hợp các con số lại với nhau, chúng ta nên (đại khái) kỳ vọng một bước nhảy vọt khác tương đương từ GPT-2 lên GPT-4 trong 4 năm tiếp sau GPT-4, vào cuối năm 2027.

Để dễ hình dung, giả sử việc huấn luyện GPT-4 mất 3 tháng. Vào năm 2027, một phòng thí nghiệm AI hàng đầu sẽ có thể huấn luyện một mô hình cấp độ GPT-4 trong vòng một phút. Đợt mở rộng quy mô năng lực tính toán hiệu dụng tính theo OOM sẽ cực kỳ ngoạn mục.
Điều đó sẽ đưa chúng ta tới đâu?
Từ GPT-2 đến GPT-4 đã đưa chúng ta từ ~trẻ mẫu giáo đến ~học sinh trung học thông minh; từ chỗ hầu như không thể đưa ra vài câu mạch lạc đến chỗ vượt qua các kỳ thi trung học và trở thành một trợ lý lập trình hữu ích. Đó là một bước nhảy điên rồ. Nếu đây là khoảng cách trí tuệ mà chúng ta sẽ đi qua một lần nữa, điều đó sẽ đưa chúng ta tới đâu? Chúng ta không nên ngạc nhiên nếu điều đó đưa chúng ta đi rất, rất xa. Có khả năng, nó sẽ đưa chúng ta đến những mô hình có thể vượt qua các Tiến sĩ và những chuyên gia giỏi nhất trong một lĩnh vực.
(Một cách thú vị để nghĩ về điều này là tiến trình hiện tại của AI đang diễn ra với tốc độ gấp khoảng 3 lần tốc độ phát triển của một đứa trẻ. Đứa trẻ 3x-tốc-độ của bạn vừa tốt nghiệp trung học; nó sẽ chiếm lấy công việc của bạn trước khi bạn kịp nhận ra!)
Một lần nữa, điều quan trọng là đừng chỉ hình dung về một ChatGPT cực kỳ thông minh: những thành tựu từ việc giải phóng tiềm năng sẽ khiến nó trông giống như một nhân viên làm việc từ xa thay thế trực tiếp, một tác nhân cực kỳ thông minh có thể suy luận, lập kế hoạch, tự sửa lỗi và biết mọi thứ về bạn cũng như công ty của bạn và có thể làm việc độc lập trên một vấn đề trong nhiều tuần.
Chúng ta đang đi đúng hướng để đạt tới AGI vào năm 2027. Các hệ thống AI này về cơ bản sẽ có thể tự động hóa hầu hết tất cả các công việc nhận thức (hãy nghĩ: tất cả các công việc có thể làm được từ xa).
Để rõ ràng — biên độ sai số là lớn. Tiến trình có thể đình trệ khi chúng ta cạn kiệt dữ liệu, nếu những đột phá thuật toán cần thiết để vượt qua rào cản dữ liệu khó khăn hơn dự kiến. Có lẽ việc giải phóng tiềm năng không đi xa được đến thế, và chúng ta bị mắc kẹt với chỉ những chatbot chuyên gia, thay vì những đồng nghiệp chuyên gia. Có lẽ các đường xu hướng kéo dài thập kỷ sẽ bị gãy, hoặc việc mở rộng quy mô học sâu thực sự chạm tường lần này. (Hoặc một đột phá thuật toán, thậm chí chỉ là việc giải phóng tiềm năng đơn giản khai phá sự dư thừa năng lực tính toán lúc chạy, có thể là một sự thay đổi hệ hình, đẩy nhanh mọi thứ hơn nữa và dẫn đến AGI sớm hơn.)

Dù thế nào đi nữa, chúng ta đang chạy đua qua các OOMs, và không cần bất kỳ niềm tin huyền bí nào, chỉ cần ngoại suy xu hướng của những đường thẳng, để coi khả năng đạt được AGI — AGI thực sự — vào năm 2027 là cực kỳ nghiêm túc.
Dường như nhiều người đang cố gắng định nghĩa thấp đi về AGI trong những ngày này, coi nó chỉ như một chatbot thực sự tốt hay gì đó đại loại vậy. Những gì tôi muốn nói là một hệ thống AI có thể tự động hóa hoàn toàn công việc của tôi hoặc của bạn bè tôi, có thể thực hiện hoàn toàn công việc của một nhà nghiên cứu hoặc kỹ sư AI. Có lẽ một số lĩnh vực, như robot, có thể mất nhiều thời gian hơn để giải quyết theo mặc định. Và việc triển khai trong xã hội, ví dụ như trong nghề y hay luật, có thể dễ dàng bị làm chậm lại bởi các lựa chọn của xã hội hoặc quy định pháp luật. Nhưng một khi các mô hình có thể tự động hóa chính việc nghiên cứu AI, bấy nhiêu là đủ — đủ để khởi động các vòng phản hồi mãnh liệt — và chúng ta có thể đạt được tiến bộ xa hơn rất nhanh chóng, khi chính các kỹ sư AI tự động giải quyết tất cả các điểm nghẽn còn lại để tự động hóa hoàn toàn mọi thứ. Đặc biệt, hàng triệu nhà nghiên cứu tự động rất có thể sẽ nén một thập kỷ tiến bộ thuật toán tiếp theo vào vòng một năm hoặc ít hơn. AGI sẽ chỉ là một hương vị nhỏ của siêu trí tuệ sắp theo sau. (Thêm về điều đó trong bài viết tiếp theo.)
Dù thế nào đi nữa, đừng mong đợi tốc độ tiến bộ chóng mặt sẽ giảm bớt. Các đường xu hướng trông có vẻ vô tội, nhưng hệ quả của chúng là rất mãnh liệt. Như với mọi thế hệ trước đó, mỗi thế hệ mô hình mới sẽ làm kinh ngạc hầu hết những người quan sát; họ sẽ hoài nghi khi rất sớm thôi, các mô hình giải quyết được những vấn đề khoa học cực kỳ khó khăn mà các Tiến sĩ phải mất nhiều ngày, khi chúng đang lướt đi trong máy tính của bạn để làm công việc của bạn, khi chúng đang viết các mã nguồn với hàng triệu dòng mã từ con số không, khi mỗi một hoặc hai năm giá trị kinh tế được tạo ra bởi các mô hình này tăng gấp 10 lần. Hãy quên khoa học viễn tưởng đi, hãy đếm các OOMs: đó là những gì chúng ta nên kỳ vọng. AGI không còn là một tưởng tượng xa vời. Việc mở rộng quy mô các kỹ thuật học sâu đơn giản đã mang lại hiệu quả, các mô hình chỉ muốn học, và chúng ta sắp thực hiện thêm một đợt tăng 100.000 lần+ nữa vào cuối năm 2027. Sẽ không lâu nữa đâu cho đến khi chúng thông minh hơn chúng ta.
GPT-4 mới chỉ là sự khởi đầu — chúng ta sẽ ở đâu sau bốn năm nữa? Đừng mắc sai lầm khi đánh giá thấp tốc độ tiến bộ nhanh chóng của học sâu.
Bài tiếp theo trong loạt bài:
II. Từ AGI đến Siêu trí tuệ: Sự bùng nổ trí tuệ

Tôi từng hoài nghi hơn về các mốc thời gian ngắn để đạt tới AGI. Một lý do là vì dường như không hợp lý khi dành sự ưu tiên cho thập kỷ này, tập trung quá nhiều xác suất đạt được AGI vào nó (có vẻ như là một sai lầm kinh điển khi nghĩ rằng "ồ chúng ta thật đặc biệt"). Tôi đã nghĩ rằng chúng ta nên không chắc chắn về những gì cần thiết để đạt được AGI, điều này sẽ dẫn đến một sự phân phối xác suất "dàn trải" hơn về thời điểm chúng ta có thể đạt được AGI.
Tuy nhiên, tôi đã thay đổi ý định: quan trọng là sự không chắc chắn của chúng ta về những gì cần thiết để đạt được AGI nên là về các OOM (năng lực tính toán hiệu dụng), thay vì về số năm.
Chúng ta đang chạy đua qua các OOM trong thập kỷ này. Ngay cả vào thời hoàng kim đã qua, Định luật Moore cũng chỉ là 1–1,5 OOM/thập kỷ. Tôi ước tính rằng chúng ta sẽ thực hiện ~5 OOM trong 4 năm, và hơn ~10 OOM trong thập kỷ này nói chung.
Về bản chất, chúng ta đang ở giữa một đợt mở rộng quy mô khổng lồ gặt hái những thành quả một lần trong thập kỷ này, và tiến trình qua các OOM sẽ chậm hơn nhiều lần sau đó. Nếu đợt mở rộng quy mô này không đưa chúng ta đến AGI trong 5-10 năm tới, nó có thể còn rất xa mới tới.
Tổng hợp lại, điều này có nghĩa là chúng ta đang chạy đua qua nhiều OOM hơn trong thập kỷ tới so với những gì chúng ta có thể thực hiện trong nhiều thập kỷ sau đó. Có thể bấy nhiêu là đủ — và chúng ta sẽ đạt được AGI sớm — hoặc chúng ta có thể phải đối mặt với một chặng đường dài và chậm chạp. Bạn và tôi có thể không đồng ý một cách hợp lý về thời điểm trung vị đạt được AGI, tùy thuộc vào việc chúng ta nghĩ việc đạt được AGI sẽ khó khăn đến mức nào — nhưng với tốc độ chúng ta đang chạy đua qua các OOM hiện nay, chắc chắn năm AGI phổ biến nhất (modal year) của bạn nên là vào khoảng cuối thập kỷ này.
Tiến bộ AI sẽ không dừng lại ở cấp độ con người. Hàng trăm triệu AGI có thể tự động hóa việc nghiên cứu AI, nén một thập kỷ tiến bộ thuật toán (hơn 5 bậc quy mô - OOMs) vào trong vòng chưa đầy một năm. Chúng ta sẽ nhanh chóng đi từ cấp độ con người đến những hệ thống AI siêu việt vượt xa con người. Sức mạnh — và cả hiểm họa — của siêu trí tuệ sẽ vô cùng ngoạn mục.

Trong bài này:
* Tự động hóa nghiên cứu AI
* Các điểm nghẽn có thể xảy ra
* Sức mạnh của siêu trí tuệ
Hãy để một cỗ máy siêu thông minh được định nghĩa là một cỗ máy có thể vượt xa tất cả các hoạt động trí tuệ của bất kỳ con người nào dù thông minh đến đâu. Vì việc thiết kế máy móc là một trong những hoạt động trí tuệ này, một cỗ máy siêu thông minh có thể thiết kế những cỗ máy thậm chí còn tốt hơn; khi đó chắc chắn sẽ có một "sự bùng nổ trí tuệ", và trí tuệ của con người sẽ bị bỏ xa phía sau. Do đó, cỗ máy siêu thông minh đầu tiên là phát minh cuối cùng mà con người cần phải thực hiện.
I. J. Good (1965)
Trong trí tưởng tượng của công chúng, những nỗi khiếp sợ của Chiến tranh Lạnh chủ yếu bắt nguồn từ Los Alamos với sự phát minh ra bom nguyên tử. Nhưng một mình "Cây Bom" (The Bomb) có lẽ đã bị đánh giá quá cao. Việc chuyển từ Bom Nguyên tử sang "Siêu Bom" (The Super) — tức bom khinh khí (bom H) — có lẽ cũng quan trọng không kém.
Trong các cuộc không kích vào Tokyo, hàng trăm máy bay ném bom đã thả hàng nghìn tấn bom thông thường xuống thành phố. Cuối năm đó, quả bom "Little Boy" thả xuống Hiroshima đã giải phóng sức tàn phá tương đương chỉ trong một thiết bị duy nhất. Nhưng chỉ 7 năm sau, quả bom khinh khí của Teller đã nhân mức công suất lên gấp một nghìn lần một lần nữa — một quả bom duy nhất có sức nổ mạnh hơn tất cả số bom đã được thả trong toàn bộ Thế chiến II cộng lại.
Bom Nguyên tử là một chiến dịch ném bom hiệu quả hơn. Siêu Bom là một thiết bị hủy diệt cả một quốc gia.
Điều tương tự cũng sẽ xảy ra với AGI và Siêu trí tuệ.
Tiến bộ AI sẽ không dừng lại ở cấp độ con người. Sau khi ban đầu học từ những ván cờ hay nhất của con người, AlphaGo bắt đầu chơi với chính nó — và nó nhanh chóng trở nên siêu việt, thực hiện những nước đi cực kỳ sáng tạo và phức tạp mà con người không bao giờ nghĩ ra được.
Chúng ta đã thảo luận về con đường dẫn đến AGI trong bài viết trước. Một khi chúng ta đạt được AGI, chúng ta sẽ quay trục quay thêm một lần nữa — hoặc hai hoặc ba lần nữa — và các hệ thống AI sẽ trở nên siêu việt — vượt xa con người. Chúng sẽ trở nên thông minh hơn bạn hoặc tôi về mặt định tính, thông minh hơn rất nhiều, có lẽ tương tự như cách bạn hoặc tôi thông minh hơn một đứa trẻ tiểu học về mặt định tính.
Bước nhảy vọt tới siêu trí tuệ sẽ đủ điên rồ ngay cả ở tốc độ tiến bộ AI nhanh chóng nhưng liên tục hiện nay (nếu chúng ta có thể nhảy vọt tới AGI trong 4 năm kể từ GPT-4, thì 4 hoặc 8 năm nữa sẽ mang lại điều gì?). Nhưng nó có thể còn nhanh hơn thế nhiều, nếu AGI tự động hóa chính việc nghiên cứu AI.
Một khi đạt được AGI, chúng sẽ không chỉ có một AGI. Tôi sẽ đi sâu vào các con số sau, nhưng: với các đội máy chủ suy luận (inference GPU fleets) vào thời điểm đó, chúng ta có thể sẽ chạy được hàng triệu bản sao AGI (có lẽ là 100 triệu bản sao tương đương con người, và sớm sau đó sẽ ở tốc độ gấp 10 lần con người). Ngay cả khi chúng chưa thể đi lại trong văn phòng hay pha cà phê, chúng sẽ có thể thực hiện nghiên cứu ML (máy học) trên máy tính. Thay vì vài trăm nhà nghiên cứu và kỹ sư tại một phòng thí nghiệm AI hàng đầu, chúng ta sẽ có gấp hơn 100.000 lần con số đó — làm việc miệt mài ngày đêm cho các đột phá thuật toán. Đúng vậy, đó là sự tự cải thiện đệ quy (recursive self-improvement), nhưng không cần khoa học viễn tưởng; chúng chỉ cần đẩy nhanh các đường xu hướng hiện có của tiến bộ thuật toán (hiệu ở mức ~0,5 OOM/năm).
Nghiên cứu AI tự động có thể thúc đẩy tiến bộ thuật toán, dẫn đến việc tăng thêm hơn 5 OOM năng lực tính toán hiệu dụng trong một năm. Các hệ thống AI mà chúng ta có vào cuối cuộc bùng nổ trí tuệ sẽ thông minh hơn con người rất nhiều.
Nghiên cứu AI tự động có lẽ có thể nén một thập kỷ nghiên cứu của con người vào chưa đầy một năm (và con số này dường như vẫn còn khiêm tốn). Đó sẽ là hơn 5 OOM, một bước nhảy vọt định tính tương đương từ GPT-2 lên GPT-4, chồng lên trên AGI — một bước nhảy định tính giống như từ trẻ mẫu giáo lên học sinh trung học thông minh, chồng lên trên các hệ thống AI vốn đã thông minh như các nhà nghiên cứu/kỹ sư AI chuyên gia.
Có một số điểm nghẽn khả thi — bao gồm năng lực tính toán hạn chế cho các thử nghiệm, tính bổ trợ với con người và tiến bộ thuật toán trở nên khó khăn hơn — tôi sẽ đề cập đến chúng, nhưng không có yếu tố nào dường như đủ để làm chậm mọi thứ lại một cách chắc chắn.
Trước khi kịp nhận ra, chúng ta sẽ có siêu trí tuệ trong tay — những hệ thống AI thông minh hơn con người rất nhiều, có khả năng thực hiện các hành vi mới lạ, sáng tạo và phức tạp mà chúng ta thậm chí không thể bắt đầu hiểu được — thậm chí có thể là một nền văn minh nhỏ với hàng tỷ cá thể như vậy. Sức mạnh của chúng cũng sẽ vô cùng lớn. Áp dụng siêu trí tuệ vào R&D (nghiên cứu và phát triển) trong các lĩnh vực khác, tiến bộ bùng nổ sẽ lan rộng từ chỉ nghiên cứu ML; sớm muộn chúng sẽ giải quyết được vấn đề robot, tạo ra những bước nhảy vọt ngoạn mục trong các lĩnh vực khoa học và công nghệ khác trong vòng vài năm, và một cuộc bùng nổ công nghiệp sẽ theo sau. Siêu trí tuệ có khả năng mang lại lợi thế quân sự quyết định và mở ra những sức mạnh hủy diệt chưa từng có. Chúng ta sẽ phải đối mặt với một trong những thời điểm căng thẳng và biến động nhất trong lịch sử nhân loại.
Chúng ta không cần tự động hóa mọi thứ — chỉ cần nghiên cứu AI. Một phản biện phổ biến đối với những tác động mang tính biến đổi của AGI là AI sẽ khó có thể làm được mọi thứ. Hãy nhìn vào robot học (robotics), những người nghi ngờ nói; đó sẽ là một vấn đề hóc búa, ngay cả khi AI đạt cấp độ trí tuệ của các Tiến sĩ. Hoặc hãy lấy việc tự động hóa R&D sinh học, điều này có thể đòi hỏi nhiều công việc thực nghiệm trong phòng thí nghiệm và thử nghiệm trên con người.
Nhưng chúng ta không cần robot — chúng ta không cần nhiều thứ — để AI tự động hóa nghiên cứu AI. Công việc của các nhà nghiên cứu và kỹ sư AI tại các phòng thí nghiệm hàng đầu có thể được thực hiện hoàn toàn ảo và không gặp phải các điểm nghẽn trong thế giới thực theo cùng một cách (mặc dù nó vẫn bị hạn chế bởi năng lực tính toán, điều mà tôi sẽ đề cập sau). Và công việc của một nhà nghiên cứu AI khá đơn giản trong bức tranh tổng thể: đọc tài liệu ML và đưa ra các câu hỏi hoặc ý tưởng mới, thực hiện các thử nghiệm để kiểm chứng những ý tưởng đó, diễn giải kết quả và lặp lại. Tất cả điều này dường như nằm trọn trong phạm vi mà những phép ngoại suy đơn giản về khả năng AI hiện tại có thể dễ dàng đưa chúng ta đến hoặc vượt xa cấp độ của những con người giỏi nhất vào cuối năm 2027.
Đáng để nhấn mạnh rằng một số đột phá máy học lớn nhất trong thập kỷ qua đã diễn ra một cách đơn giản và "thủ công" như thế nào: "ồ, chỉ cần thêm một số phép chuẩn hóa (LayerNorm/BatchNorm)" hoặc "thực hiện f(x)+x thay vì f(x) (kết nối dư - residual connections)" hoặc "sửa một lỗi triển khai (định luật mở rộng quy mô Kaplan -> Chinchilla)". Nghiên cứu AI có thể được tự động hóa. Và tự động hóa nghiên cứu AI là tất cả những gì cần thiết để khởi động các vòng phản hồi phi thường.
Chúng ta sẽ có thể chạy hàng triệu bản sao (và sớm đạt tốc độ gấp 10 lần con người) của các nhà nghiên cứu AI tự động. Ngay cả vào năm 2027, chúng ta nên kỳ vọng các đội máy chủ GPU lên tới hàng chục triệu. Riêng các cụm máy chủ huấn luyện sẽ tiến tới quy mô lớn hơn ~3 OOM, đưa chúng ta tới hơn 10 triệu bản sao tương đương A100. Các đội máy chủ suy luận thậm chí sẽ còn lớn hơn nhiều.
Điều đó cho phép chúng ta chạy hàng triệu bản sao nhà nghiên cứu AI tự động của mình, có lẽ là 100 triệu bản sao tương đương nhà nghiên cứu con người, làm việc cả ngày lẫn đêm. Có một số giả định làm cơ sở cho các con số chính xác này, bao gồm việc con người "suy nghĩ" ở mức 100 token/phút (chỉ là một ước tính thô về bậc quy mô, ví dụ hãy xem xét độc thoại nội tâm của bạn) và ngoại suy các xu hướng lịch sử cùng định luật mở rộng quy mô Chinchilla về chi phí suy luận trên mỗi token cho các mô hình tiên phong vẫn ở mức tương đương. Chúng ta cũng muốn dành một phần GPU để chạy các thử nghiệm và huấn luyện các mô hình mới.
Một cách nghĩ khác là với các đội máy chủ suy luận vào năm 2027, chúng ta có thể tạo ra lượng token tương đương với toàn bộ internet mỗi ngày. Dù thế nào đi nữa, các con số chính xác không quan trọng bằng một minh chứng đơn giản về tính khả thi.
Hơn nữa, các nhà nghiên cứu AI tự động của chúng ta có thể sớm chạy ở tốc độ nhanh hơn nhiều so với con người:

Nghĩa là: hãy kỳ vọng 100 triệu nhà nghiên cứu tự động, mỗi người làm việc với tốc độ gấp 100 lần con người không lâu sau khi chúng ta bắt đầu tự động hóa được nghiên cứu AI. Mỗi người trong số họ có thể hoàn thành khối lượng công việc của một năm chỉ trong vài ngày. Sự gia tăng nỗ lực nghiên cứu — so với vài trăm nhà nghiên cứu con người ít ỏi tại một phòng thí nghiệm AI hàng đầu ngày nay, làm việc với tốc độ 1x khiêm tốn — sẽ là phi thường.
Điều này có thể dễ dàng thúc đẩy mạnh mẽ các xu hướng tiến bộ thuật toán hiện có, nén một thập kỷ tiến bộ vào trong một năm. Chúng ta không cần giả định bất cứ điều gì hoàn toàn mới lạ để nghiên cứu AI tự động có thể tăng tốc độ tiến bộ AI một cách mãnh liệt. Điểm qua các con số trong bài viết trước, chúng ta thấy rằng tiến bộ thuật toán là động lực trung tâm của sự phát triển học sâu trong thập kỷ qua; chúng ta đã ghi nhận đường xu hướng ~0,5 OOM/năm chỉ tính riêng trên hiệu quả thuật toán, cộng thêm các thành tựu thuật toán lớn từ việc giải phóng tiềm năng. (Tôi nghĩ tầm quan trọng của tiến bộ thuật toán đã bị nhiều người đánh giá thấp, và việc đánh giá đúng nó là rất quan trọng để hiểu được khả năng xảy ra bùng nổ trí tuệ.)
Liệu hàng triệu nhà nghiên cứu AI tự động (sớm làm việc với tốc độ gấp 10 hay 100 lần con người) có thể nén tiến bộ thuật toán mà các nhà nghiên cứu con người sẽ tìm thấy trong một thập kỷ vào một năm thay thế? Đó sẽ là hơn 5 OOM trong một năm.
Đừng chỉ tưởng tượng về 100 triệu thực tập sinh kỹ sư phần mềm trẻ tuổi ở đây (chúng ta sẽ có họ sớm hơn, trong vài năm tới!). Các nhà nghiên cứu AI tự động thực sự sẽ rất thông minh — và bên cạnh lợi thế định lượng thô của mình, các nhà nghiên cứu AI tự động sẽ có những lợi thế khổng lồ khác so với nhà nghiên cứu con người:
Hãy tưởng tượng một Alec Radford tự động — hãy tưởng tượng 100 triệu Alec Radford tự động. Tôi nghĩ hầu như mọi nhà nghiên cứu tại OpenAI đều đồng ý rằng nếu họ có 10 Alec Radford, chứ chưa nói đến 100 hay 1.000 hay 1 triệu người chạy ở tốc độ gấp 10 hay 100 lần con người, họ có thể giải quyết rất nhiều vấn đề của mình một cách nhanh chóng. Ngay cả với các điểm nghẽn khác, việc nén một thập kỷ tiến bộ thuật toán vào một năm dường như là rất khả thi. (Mức tăng tốc 10 lần từ nỗ lực nghiên cứu gấp một triệu lần dường như vẫn là một ước tính khiêm tốn.)
Đó sẽ là hơn 5 OOM ngay tại đó. 5 OOM thành tựu thuật toán sẽ là một đợt mở rộng quy mô tương tự như những gì đã tạo ra bước nhảy vọt từ GPT-2 lên GPT-4, một bước nhảy vọt về năng lực từ ~trẻ mẫu giáo lên ~học sinh trung học thông minh. Hãy tưởng tượng một bước nhảy định tính như vậy chồng lên trên AGI, chồng lên trên Alec Radford.
Cực kỳ khả thi là chúng sẽ đi từ AGI đến siêu trí tuệ rất nhanh chóng, có lẽ trong chưa đầy một năm.
Mặc dù câu chuyện cơ bản này gây ấn tượng mạnh mẽ — và được hỗ trợ bởi các mô hình kinh tế kỹ lưỡng — có một số điểm nghẽn thực tế và khả thi có lẽ sẽ làm chậm lại cuộc bùng nổ trí tuệ từ nghiên cứu AI tự động.
Tôi sẽ đưa ra tóm tắt ở đây:
Dù bạn có đồng ý với dạng mạnh nhất của các lập luận này hay không — liệu chúng ta sẽ có một cuộc bùng nổ trí tuệ trong chưa đầy 1 năm, hay mất vài năm — thì có một điều rõ ràng: chúng ta phải đối mặt với khả năng xuất hiện của siêu trí tuệ.
Các hệ thống AI mà chúng ta có thể có vào cuối thập kỷ này sẽ mạnh mẽ đến mức không thể tưởng tượng nổi.

Trong cuộc bùng nổ trí tuệ, tiến bộ bùng nổ ban đầu chỉ diễn ra trong lĩnh vực hẹp là nghiên cứu AI tự động. Khi chúng ta có được siêu trí tuệ và áp dụng hàng tỷ tác nhân (giờ đã siêu thông minh) của mình vào R&D trên nhiều lĩnh vực, tôi kỳ vọng tiến bộ bùng nổ sẽ lan rộng:

Việc tất cả những điều này diễn ra như thế nào trong thập kỷ 2030 là điều khó dự đoán. Nhưng có một điều chắc chắn: chúng ta sẽ nhanh chóng bị đẩy vào tình huống cực đoan nhất mà nhân loại từng đối mặt.
Các hệ thống AI cấp độ con người, AGI, vốn đã mang lại những hệ quả to lớn — nhưng theo một nghĩa nào đó, chúng chỉ đơn thuần là phiên bản hiệu quả hơn của những gì chúng ta đã biết. Nhưng rất có thể, chỉ trong vòng một năm, chúng ta sẽ chuyển sang những hệ thống xa lạ hơn nhiều, những hệ thống mà sự hiểu biết và khả năng — sức mạnh thô của chúng — sẽ vượt xa ngay cả sức mạnh tổng hợp của nhân loại. Có một khả năng thực tế là chúng ta sẽ mất kiểm soát, khi chúng ta bị buộc phải trao niềm tin cho các hệ thống AI trong quá trình chuyển đổi nhanh chóng này.
Nói chung, mọi thứ sẽ bắt đầu diễn ra cực kỳ nhanh chóng. Và thế giới sẽ bắt đầu trở nên điên rồ. Sự bùng nổ trí tuệ và giai đoạn ngay sau khi có siêu trí tuệ sẽ là một trong những thời kỳ biến động nhất, căng thẳng nhất, nguy hiểm nhất và điên rồ nhất từng có trong lịch sử nhân loại.
Và đến cuối thập kỷ này, chúng ta có thể sẽ ở ngay giữa tâm bão.
Một sự gia tốc kỹ thuật - tư bản phi thường nhất đã được khởi động. Khi doanh thu từ AI tăng trưởng nhanh chóng, hàng nghìn tỷ đô la sẽ được đổ vào việc xây dựng GPU, trung tâm dữ liệu và nguồn điện trước khi kết thúc thập kỷ. Cuộc huy động công nghiệp, bao gồm việc tăng sản lượng điện của Mỹ thêm hàng chục phần trăm, sẽ diễn ra vô cùng mãnh liệt.

Trong bài này:
* Năng lực tính toán huấn luyện
* Năng lực tính toán tổng thể
* Liệu điều này sẽ được thực hiện? Liệu có thể thực hiện được không?
* Doanh thu từ AI
* Các tiền lệ lịch sử
* Điện năng
* Chip
* Các cụm máy chủ của thế giới dân chủ
Anh thấy đấy, tôi đã nói với anh rằng điều đó không thể thực hiện được nếu không biến cả đất nước thành một công xưởng. Anh đã làm đúng như vậy.
Niels Bohr (nói với Edward Teller, khi biết về quy mô của Dự án Manhattan vào năm 1944)
...
Trước đó, chúng ta đã tìm thấy đường xu hướng tăng trưởng năng lực tính toán huấn luyện AI ở mức khoảng ~0,5 OOM/năm. Nếu xu hướng này tiếp tục trong phần còn lại của thập kỷ, điều đó sẽ có ý nghĩa gì đối với các cụm máy chủ huấn luyện lớn nhất?

...
Các con số trên chỉ là ước tính sơ bộ cho các cụm máy chủ huấn luyện lớn nhất. Tổng vốn đầu tư có khả năng còn lớn hơn nhiều: một phần lớn GPU có thể sẽ được sử dụng cho việc suy luận (GPU thực sự chạy các hệ thống AI cho các sản phẩm), và có thể có nhiều bên cùng tham gia cuộc đua với các cụm máy chủ khổng lồ.

...
...
Các phòng thí nghiệm AI hàng đầu của quốc gia đang coi an ninh chỉ là một vấn đề phụ. Hiện tại, về cơ bản họ đang dâng các bí mật then chốt về AGI cho ĐCSTQ trên một chiếc khay bạc. Việc bảo vệ các bí mật và trọng số AGI trước các mối đe dọa từ các tác nhân quốc gia sẽ là một nỗ lực khổng lồ, và chúng ta đang không đi đúng hướng.
Họ gặp nhau vào buổi tối tại văn phòng của Wigner. "Szilard đã phác thảo các dữ liệu từ Columbia," Wheeler thuật lại, "và những dấu hiệu ban đầu cho thấy có ít nhất hai neutron thứ cấp xuất hiện từ mỗi lần phân hạch do neutron gây ra. Điều này chẳng phải có nghĩa là một vụ nổ hạt nhân chắc chắn có thể xảy ra sao?" Không nhất thiết, Bohr phản bác.
"Chúng tôi đã cố gắng thuyết phục ông ấy," Teller viết, "rằng chúng ta nên tiếp tục nghiên cứu phân hạch nhưng không được công bố kết quả. Chúng ta nên giữ bí mật các kết quả, e rằng quân phát xít biết được và chế tạo ra bom nguyên tử trước."
"Bohr khăng khăng rằng chúng ta sẽ không bao giờ thành công trong việc tạo ra năng lượng hạt nhân và ông cũng nhấn mạnh rằng sự bí mật không bao giờ được phép đưa vào vật lý."
Richard Rhodes, The Making of the Atomic Bomb (tr. 430)
Theo lộ trình hiện tại, các phòng thí nghiệm AGI hàng đầu của Trung Quốc sẽ không nằm ở Bắc Kinh hay Thượng Hải — chúng sẽ nằm ở San Francisco và London. Trong vài năm tới, rõ ràng là các bí mật về AGI sẽ là những bí mật quốc phòng quan trọng nhất của Hoa Kỳ — đáng được đối xử ngang hàng với bản thiết kế máy ném bom B-21 hay tàu ngầm lớp Columbia, chứ chưa nói đến những "bí mật hạt nhân" huyền thoại — nhưng ngày nay, chúng ta đang đối xử với chúng như những phần mềm SaaS ngẫu nhiên nào đó. Với tốc độ này, về cơ bản chúng ta chỉ đang dâng siêu trí tuệ cho ĐCSTQ.
Tất cả hàng nghìn tỷ đô la chúng ta sẽ đầu tư, sự huy động sức mạnh công nghiệp của Mỹ, những nỗ lực của những bộ não sáng láng nhất — không điều nào trong số đó còn ý nghĩa nếu Trung Quốc hoặc những bên khác có thể đơn giản là đánh cắp các trọng số mô hình (tất cả những gì một mô hình AI hoàn chỉnh có, tất cả những gì AGI sẽ là, chỉ là một tệp lớn trên máy tính) hoặc các bí mật thuật toán then chốt (những đột phá kỹ thuật then chốt cần thiết để xây dựng AGI).
Các phòng thí nghiệm AI hàng đầu của Mỹ tự tuyên bố đang xây dựng AGI: họ tin rằng công nghệ họ đang chế tạo sẽ trở thành vũ khí mạnh nhất mà nước Mỹ từng tạo ra trước khi thập kỷ này kết thúc. Nhưng họ không đối xử với nó như vậy. Họ đo lường những nỗ lực an ninh của mình dựa trên tiêu chuẩn của các "công ty khởi nghiệp công nghệ ngẫu nhiên", chứ không phải các "dự án quốc phòng trọng điểm". Khi cuộc đua AGI tăng tốc — khi rõ ràng là siêu trí tuệ sẽ mang tính quyết định tuyệt đối trong cạnh tranh quân sự quốc tế — chúng ta sẽ phải đối mặt với toàn bộ sức mạnh của hoạt động gián điệp nước ngoài. Hiện tại, các phòng thí nghiệm thậm chí còn khó có thể chống lại các hacker nghiệp dư (scriptkiddies), chứ đừng nói đến việc có "an ninh cấp độ chống Triều Tiên", hay sẵn sàng đối mặt với Bộ An ninh Quốc gia Trung Quốc đang huy động toàn lực.
Và điều này sẽ không chỉ quan trọng trong nhiều năm tới. Chắc chắn rồi, ai quan tâm nếu trọng số GPT-4 bị đánh cắp — điều thực sự quan trọng là chúng ta có thể bảo vệ các trọng số AGI trong tương lai, vì vậy bạn có thể nói rằng chúng ta còn vài năm nữa. (Dù nếu chúng ta xây dựng AGI vào năm 2027, chúng ta thực sự phải hành động ngay!) Nhưng các phòng thí nghiệm AI đang phát triển các bí mật thuật toán — những đột phá kỹ thuật then chốt, có thể gọi là bản thiết kế — cho AGI ngay lúc này. An ninh cấp độ AGI cho các bí mật thuật toán là cần thiết từ nhiều năm trước khi cần an ninh cấp độ AGI cho các trọng số. Những đột phá thuật toán này sẽ quan trọng hơn một cụm máy chủ lớn gấp 10 hay 100 lần trong vài năm tới — đây là vấn đề lớn hơn nhiều so với việc kiểm soát xuất khẩu năng lực tính toán mà Chính phủ Mỹ đã (một cách sáng suốt!) đang theo đuổi quyết liệt. Hiện tại, bạn thậm chí không cần phải tổ chức một chiến dịch gián điệp kịch tính để đánh cắp những bí mật này: chỉ cần đến bất kỳ bữa tiệc nào ở San Francisco hoặc nhìn qua cửa sổ văn phòng.
Sự thất bại của chúng ta hôm nay sẽ sớm trở nên không thể cứu vãn: trong 12-24 tháng tới, chúng ta sẽ làm rò rỉ những đột phá then chốt về AGI cho ĐCSTQ. Đó sẽ là nỗi hối tiếc lớn nhất của giới an ninh quốc gia trước khi thập kỷ kết thúc.
Việc bảo vệ thế giới tự do trước các quốc gia độc tài đang bị đe dọa — và một khoảng cách dẫn đầu an toàn sẽ là vùng đệm cần thiết để chúng ta có lề sai số cho việc thực hiện an toàn AI đúng cách. Hoa Kỳ đang có lợi thế trong cuộc đua AGI. Nhưng chúng ta sẽ đánh mất lợi thế này nếu không nghiêm túc về an ninh sớm. Giải quyết vấn đề này, ngay bây giờ, có lẽ là điều quan trọng nhất chúng ta cần làm hôm nay để đảm bảo AGI diễn ra tốt đẹp.
Quá nhiều người thông minh đánh giá thấp hoạt động gián điệp.
Khả năng của các quốc gia và các cơ quan tình báo của họ là cực kỳ đáng gờm. Ngay cả trong thời điểm bình thường (và từ những gì ít ỏi chúng ta biết công khai), các quốc gia đã có thể:
Trung Quốc đã tham gia vào hoạt động gián điệp công nghiệp trên diện rộng; Giám đốc FBI tuyên bố Trung Quốc có một chiến dịch tấn công mạng lớn hơn "tất cả các quốc gia lớn cộng lại". Và chỉ vài tháng trước, Bộ trưởng Tư pháp Mỹ đã thông báo về việc bắt giữ một công dân Trung Quốc đã đánh cắp mã AI then chốt từ Google để mang về nước.
Nhưng đó mới chỉ là sự khởi đầu. Chúng ta phải chuẩn bị cho việc các đối thủ của mình "thức tỉnh với AGI" trong vài năm tới. AI sẽ trở thành ưu tiên số 1 của mọi cơ quan tình báo trên thế giới. Trong tình huống đó, họ sẽ sẵn sàng sử dụng các phương tiện phi thường và trả bất kỳ giá nào để xâm nhập vào các phòng thí nghiệm AI.
Có hai tài sản then chốt mà chúng ta phải bảo vệ: trọng số mô hình (đặc biệt khi chúng ta tiến gần đến AGI, nhưng đòi hỏi nhiều năm chuẩn bị và thực hành để thực hiện đúng) và các bí mật thuật toán (bắt đầu từ ngày hôm qua).
Một mô hình AI chỉ là một tệp lớn chứa các con số trên một máy chủ. Nó có thể bị đánh cắp. Tất cả những gì đối thủ cần để san bằng hàng nghìn tỷ đô la, những bộ não thông minh nhất và hàng thập kỷ làm việc của bạn là đánh cắp tệp này. (Hãy tưởng tượng nếu quân phát xít có được bản sao chính xác của mọi quả bom nguyên tử được chế tạo tại Los Alamos.)
Nếu chúng ta không thể giữ an toàn cho trọng số mô hình, chúng ta chỉ đang xây dựng AGI cho ĐCSTQ (và với quỹ đạo an ninh hiện tại của các phòng thí nghiệm AI, thậm chí là cho Triều Tiên).
Ngoài cạnh tranh quốc gia, việc bảo vệ trọng số mô hình cũng rất quan trọng để ngăn chặn các thảm họa AI. Mọi biện pháp bảo vệ của chúng ta sẽ vô ích nếu một tác nhân xấu (ví dụ: một tổ chức khủng bố hoặc quốc gia bất hảo) có thể đơn giản là đánh cắp mô hình và làm bất cứ điều gì họ muốn, vượt qua mọi lớp an toàn. Bất kỳ vũ khí hủy diệt hàng loạt mới nào mà siêu trí tuệ có thể phát minh ra sẽ nhanh chóng lan rộng tới hàng chục quốc gia bất hảo. Hơn nữa, an ninh là lớp phòng thủ đầu tiên chống lại các hệ thống AI mất kiểm soát hoặc bị căn chỉnh sai.
Kịch bản khiến tôi lo lắng nhất là nếu Trung Quốc hoặc một đối thủ khác có thể đánh cắp các trọng số mô hình nhà-nghiên-cứu-AI-tự-động ngay trước ngưỡng cửa của một cuộc bùng nổ trí tuệ. Trung Quốc có thể ngay lập tức sử dụng chúng để tự động hóa nghiên cứu AI của chính họ (ngay cả khi trước đó họ đang tụt lại xa phía sau) — và khởi động cuộc bùng nổ trí tuệ của riêng họ. Bất kỳ sự dẫn đầu nào của Mỹ cũng sẽ tan biến.
Hiện tại chúng ta còn cách rất xa mức an ninh đủ để bảo vệ các trọng số. Google DeepMind (có lẽ là phòng thí nghiệm AI có an ninh tốt nhất) thừa nhận họ mới chỉ ở mức độ an ninh 0 (chỉ có các biện pháp cơ bản nhất). Nếu chúng ta có được AGI và siêu trí tuệ sớm, chúng ta sẽ thực sự dâng tặng nó cho các nhóm khủng bố và mọi kẻ độc tài điên rồ ngoài kia!
Điều quan trọng là việc phát triển cơ sở hạ tầng cho an ninh trọng số có lẽ phải mất nhiều năm — nếu chúng ta nghĩ AGI trong ~3-4 năm tới là một khả năng thực tế và chúng ta cần an ninh trọng số cấp độ quốc gia vào lúc đó, chúng ta cần phải triển khai các nỗ lực khẩn cấp ngay bây giờ. Việc bảo vệ trọng số sẽ đòi hỏi những đổi mới trong phần cứng và thiết kế cụm máy chủ hoàn toàn khác biệt; và an ninh ở cấp độ này không thể đạt được qua đêm mà cần các chu kỳ lặp lại.
Mặc dù mọi người đang bắt đầu nhận thức được nhu cầu bảo vệ trọng số, nhưng có lẽ điều thậm chí còn quan trọng hơn lúc này — và bị đánh giá thấp một cách đáng kể — là bảo vệ các bí mật thuật toán.
Đánh cắp các bí mật thuật toán sẽ có giá trị tương đương với việc sở hữu một cụm máy chủ lớn gấp 10 lần hoặc hơn:
* Theo xu hướng hiện tại, chúng ta nên kỳ vọng sẽ có thêm nhiều bậc quy mô (OOM) bí mật thuật toán từ nay đến khi có AGI. Mặc định, tôi kỳ vọng các phòng thí nghiệm Mỹ sẽ dẫn đầu nhiều năm; nếu họ có thể bảo vệ các bí mật của mình, điều này có thể dễ dàng có giá trị tương đương với năng lực tính toán gấp 10-100 lần.
* Quan trọng hơn nữa, chúng ta có thể đang phát triển những đột phá then chốt về hệ hình cho AGI ngay lúc này. Việc mở rộng quy mô các mô hình hiện tại sẽ chạm tường: rào cản dữ liệu. Các phòng thí nghiệm AI tiên phong đang miệt mài làm việc cho những gì sắp tới, từ RL đến dữ liệu tổng hợp. Những phát minh của họ sẽ quan trọng như việc phát minh ra hệ hình LLM ban đầu vài năm trước, và chúng sẽ là chìa khóa để xây dựng các hệ thống vượt xa cấp độ con người.
Nói một cách đơn giản, tôi nghĩ việc thất bại trong việc bảo vệ các bí mật thuật toán có lẽ là cách khả thi nhất để Trung Quốc có thể duy trì khả năng cạnh tranh trong cuộc đua AGI.
An ninh của các phòng thí nghiệm AI hiện nay không tốt hơn nhiều so với "an ninh của một công ty khởi nghiệp ngẫu nhiên". Việc trực tiếp bán các bí mật AGI cho ĐCSTQ ít nhất còn thành thực hơn.
… Đây có phải là những gì chúng ta thấy ở OpenAI hay bất kỳ phòng thí nghiệm AI nào khác của Mỹ không? Không. Thực tế, những gì chúng ta thấy là ngược lại — an ninh tương đương với một miếng pho mát Thụy Sĩ (đầy lỗ hổng). Sự thâm nhập của Trung Quốc vào các phòng thí nghiệm này sẽ cực kỳ dễ dàng bằng bất kỳ phương pháp gián điệp công nghiệp nào, chẳng hạn như chỉ đơn giản là hối lộ nhân viên vệ sinh để cắm USB vào máy tính xách tay. Giả định của riêng tôi là tất cả các phòng thí nghiệm AI như vậy của Mỹ đã bị thâm nhập hoàn toàn và Trung Quốc đang tải xuống hàng đêm tất cả các nghiên cứu và mã AI của Mỹ NGAY BÂY GIỜ…
Marc Andreessen
Khi Trung Quốc bắt đầu thực sự hiểu được tầm quan trọng của AGI, chúng ta nên kỳ vọng toàn bộ sức mạnh của các nỗ lực gián điệp của họ sẽ được huy động; hãy nghĩ đến hàng tỷ đô la được đầu tư, hàng nghìn nhân viên và các biện pháp cực đoan (ví dụ: các đội đặc nhiệm đột kích) dành riêng cho việc xâm nhập các nỗ lực AGI của Mỹ. An ninh cho AGI và siêu trí tuệ sẽ đòi hỏi những gì?
Nói ngắn gọn, điều này chỉ có thể thực hiện được với sự giúp đỡ của chính phủ. Các công ty tư nhân đơn giản là không có chuyên môn về các cuộc tấn công từ các tác nhân quốc gia. Để đưa xác suất bị đánh cắp xuống mức một con số, chúng ta cần một dự án của chính phủ.
Để hình dung về những gì an ninh chống lại các tác nhân quốc gia thực sự có nghĩa:
* Các trung tâm dữ liệu cách ly hoàn toàn (airgapped), với an ninh vật lý ngang hàng với các căn cứ quân sự kiên cố nhất.
* Những tiến bộ kỹ thuật mới về tính toán bảo mật (confidential compute) / mã hóa phần cứng và sự giám sát cực độ đối với toàn bộ chuỗi cung ứng phần cứng.
* Tất cả nhân sự nghiên cứu làm việc trong các cơ sở SCIF (Sensitive Compartmented Information Facility - Cơ sở Thông tin Nhạy cảm được Phân vùng).
* Việc thẩm tra nhân sự và kiểm tra an ninh cực kỳ khắt khe, giám sát liên tục và hạn chế đáng kể quyền tự do thôi việc, cùng sự phân vùng thông tin nghiêm ngặt.
* Các biện pháp kiểm soát nội bộ mạnh mẽ, ví dụ: cần nhiều chữ ký số đồng thời để chạy bất kỳ mã nguồn nào.
* Giới hạn nghiêm ngặt đối với bất kỳ thư viện bên ngoài nào.
* Việc kiểm tra xâm nhập (pen-testing) cường độ cao liên tục bởi NSA hoặc các đơn vị tương tự.
Một số người lập luận rằng các biện pháp an ninh nghiêm ngặt và sự phiền hà đi kèm là không đáng vì chúng sẽ làm chậm các phòng thí nghiệm AI của Mỹ quá nhiều. Nhưng tôi nghĩ đó là một sai lầm: đây là vấn đề "bi kịch của mảnh đất chung". Đối với lợi ích thương mại của một phòng thí nghiệm cụ thể, các biện pháp an ninh gây chậm trễ 10% có thể là bất lợi trong cạnh tranh. Nhưng lợi ích quốc gia rõ ràng sẽ được phục vụ tốt hơn nếu mọi phòng thí nghiệm đều sẵn sàng chấp nhận sự phiền hà đó. Việc Mỹ duy trì tiến bộ thuật toán với tốc độ 90% nhưng giữ được lợi thế quốc gia rõ ràng tốt hơn việc duy trì tốc độ 100% nhưng lợi thế quốc gia bằng 0% (vì mọi thứ đều bị đánh cắp ngay lập tức)!
Có một sự mâu thuẫn tinh thần thực sự về vấn đề an ninh tại các phòng thí nghiệm AI hàng đầu. Họ dõng dạc tuyên bố đang xây dựng AGI trong thập kỷ này. Họ nhấn mạnh rằng sự dẫn đầu của Mỹ về AGI sẽ mang tính quyết định đối với an ninh quốc gia. Nhưng thực tế về an ninh lại hoàn toàn tách biệt với điều đó. Bất cứ khi nào đến lúc phải đưa ra những lựa chọn khó khăn để ưu tiên an ninh, thái độ của công ty khởi nghiệp và lợi ích thương mại luôn thắng thế so với lợi ích quốc gia. Cố vấn an ninh quốc gia sẽ bị suy sụp tinh thần nếu ông hiểu được mức độ an ninh tại các phòng thí nghiệm AI hàng đầu của đất nước.
Sự thật là, a) trong 12-24 tháng tới, chúng ta sẽ phát triển các đột phá thuật toán then chốt cho AGI, và nhanh chóng để lộ chúng cho ĐCSTQ, và b) chúng ta thậm chí không đi đúng hướng để các trọng số mô hình được an toàn trước các tác nhân như Triều Tiên, chứ đừng nói đến nỗ lực tổng lực của Trung Quốc, vào thời điểm chúng ta xây dựng xong AGI. "An ninh tốt cho một công ty khởi nghiệp" đơn giản là không đủ, và chúng ta còn rất ít thời gian trước khi những tổn hại nghiêm trọng đối với an ninh quốc gia của Hoa Kỳ trở nên không thể đảo ngược.
Chúng ta đang phát triển loại vũ khí mạnh nhất mà nhân loại từng tạo ra. Các bí mật thuật toán mà chúng ta đang phát triển, ngay lúc này, theo đúng nghĩa đen là những bí mật quốc phòng quan trọng nhất của quốc gia. Vậy mà an ninh của các phòng thí nghiệm AI có lẽ còn tệ hơn một nhà thầu quốc phòng ngẫu nhiên đang sản xuất đinh vít.
Thật điên rồ.
Về cơ bản, không có điều gì khác chúng ta làm — về cạnh tranh quốc gia hay về an toàn AI — còn ý nghĩa nếu chúng ta không sớm khắc phục điều này.
Việc kiểm soát một cách đáng tin cậy các hệ thống AI thông minh hơn chúng ta rất nhiều là một vấn đề kỹ thuật chưa có lời giải. Và mặc dù đó là một vấn đề có thể giải quyết được, mọi thứ rất dễ đi chệch hướng trong một cuộc bùng nổ trí tuệ nhanh chóng. Việc quản lý điều này sẽ vô cùng căng thẳng; thất bại có thể dễ dàng dẫn đến thảm họa.

...

...

...
Siêu trí tuệ sẽ mang lại lợi thế kinh tế và quân sự quyết định. Trung Quốc hoàn toàn chưa rời bỏ cuộc chơi. Trong cuộc đua tới AGI, sự sinh tồn của thế giới tự do đang bị đe dọa. Liệu chúng ta có thể duy trì vị thế dẫn đầu trước các cường quốc độc tài? Và liệu chúng ta có thể tránh được sự tự hủy diệt trên con đường đó?

...
Khi cuộc đua tới AGI tăng tốc, nhà nước an ninh quốc gia sẽ tham gia vào. Chính phủ Mỹ sẽ bừng tỉnh sau cơn mê, và vào khoảng năm 27/28, chúng ta sẽ có một hình thức dự án AGI của chính phủ. Không một công ty khởi nghiệp nào có thể xử lý được siêu trí tuệ. Ở một nơi nào đó trong một cơ sở SCIF (Cơ sở Thông tin Nhạy cảm được Phân vùng), giai đoạn cuối (endgame) sẽ bắt đầu.

"Chúng ta phải tò mò muốn tìm hiểu xem làm thế nào một tập hợp các đối tượng như vậy — hàng trăm nhà máy điện, hàng nghìn quả bom, hàng chục nghìn người tập trung trong các cơ sở quốc gia — có thể được truy nguyên từ một vài người ngồi tại bàn thí nghiệm thảo luận về hành vi kỳ lạ của một loại nguyên tử."
Spencer R. Weart
Nhiều kế hoạch về "quản trị AI" đang được đưa ra hiện nay, từ cấp phép hệ thống AI tiên phong, tiêu chuẩn an toàn cho đến đám mây công cộng với vài trăm triệu năng lực tính toán cho giới học thuật. Những kế hoạch này có vẻ thiện chí — nhưng đối với tôi, dường như chúng đang mắc sai lầm về phân loại.
Tôi thấy thật điên rồ khi cho rằng chính phủ Mỹ sẽ để một công ty khởi nghiệp ngẫu nhiên ở San Francisco phát triển siêu trí tuệ. Hãy tưởng tượng nếu chúng ta phát triển bom nguyên tử bằng cách để Uber tự ứng biến.
Siêu trí tuệ — hệ thống AI thông minh hơn con người rất nhiều — sẽ có sức mạnh khổng lồ, từ việc phát triển vũ khí mới đến thúc đẩy sự bùng nổ tăng trưởng kinh tế. Siêu trí tuệ sẽ là tâm điểm của cạnh tranh quốc tế; một khoảng cách dẫn đầu chỉ vài tháng cũng có thể mang tính quyết định trong xung đột quân sự.
Giống như nhiều nhà khoa học trước chúng ta, những bộ não lớn ở San Francisco hy vọng họ có thể kiểm soát vận mệnh của "con quỷ" mà họ đang khai sinh. Hiện tại, họ vẫn có thể; vì họ nằm trong số ít những người có nhận thức tình huống, những người hiểu mình đang xây dựng cái gì. Nhưng trong vài năm tới, thế giới sẽ thức tỉnh. Nhà nước an ninh quốc gia cũng vậy. Lịch sử sẽ quay trở lại một cách huy hoàng.
Cũng như nhiều lần trước đây — đại dịch Covid, Thế chiến II — nước Mỹ dường như đang ngủ quên sau tay lái — trước khi, đột ngột, chính phủ chuyển số một cách phi thường nhất. Sẽ có một khoảnh khắc — chỉ trong vài năm tới, chỉ sau vài bước nhảy vọt "cấp độ 2023" nữa về năng lực mô hình — nơi mọi thứ trở nên rõ ràng: chúng ta đang ở ngưỡng cửa của AGI, và siêu trí tuệ sẽ nối tiếp ngay sau đó. Mặc dù các cơ chế chính xác có thể thay đổi, theo cách này hay cách khác, Chính phủ Mỹ sẽ nắm quyền điều khiển; các phòng thí nghiệm hàng đầu sẽ ("tự nguyện") hợp nhất; Quốc hội sẽ chi hàng nghìn tỷ đô la cho chip và điện năng; một liên minh các nền dân chủ sẽ được hình thành.
Các công ty khởi nghiệp rất giỏi trong nhiều việc — nhưng một mình công ty khởi nghiệp đơn giản là không được trang bị đủ để phụ trách dự án quốc phòng quan trọng nhất của Hoa Kỳ. Chúng ta sẽ cần sự tham gia của chính phủ để có được dù chỉ một tia hy vọng phòng thủ trước mối đe dọa gián điệp tổng lực; nỗ lực của các công ty AI tư nhân chẳng khác nào trực tiếp dâng siêu trí tuệ cho ĐCSTQ. Chúng ta sẽ cần chính phủ để đảm bảo một chuỗi mệnh lệnh tỉnh táo; bạn không thể để những CEO ngẫu nhiên (hoặc các hội đồng quản trị phi lợi nhuận ngẫu nhiên) nắm giữ nút bấm hạt nhân. Chúng ta sẽ cần chính phủ để huy động một liên minh dân chủ để giành chiến thắng trong cuộc đua với các cường quốc độc tài, và rèn giũa (cũng như thực thi) một chế độ phi phổ biến cho phần còn lại của thế giới. Tôi ước gì mọi chuyện không phải như vậy — nhưng chúng ta sẽ cần đến chính phủ.
Một bước ngoặt in sâu vào ký ức của tôi là giai đoạn từ cuối tháng 2 đến giữa tháng 3 năm 2020. Trong những tuần cuối cùng của tháng 2 và đầu tháng 3 đó, tôi đã hoàn toàn tuyệt vọng: rõ ràng là chúng ta đang ở trên đường cong hàm mũ của Covid: một bệnh dịch sắp quét qua đất nước, sự sụp đổ của các bệnh viện là không thể tránh khỏi — vậy mà hầu như không ai coi trọng nó. Thị trưởng New York khi đó vẫn gạt bỏ nỗi sợ Covid là phân biệt chủng tộc và khuyến khích mọi người đi xem các buổi diễn Broadway.

Vậy mà chỉ trong vòng vài tuần, cả nước đóng cửa và Quốc hội đã chi hàng nghìn tỷ đô la (đúng nghĩa là >10% GDP). Nhìn thấy hàm số mũ có thể đi đến đâu trước thời hạn là quá khó, nhưng khi mối đe dọa đủ gần, đủ mang tính sinh tồn, những lực lượng phi thường đã được giải phóng. Phản ứng tuy muộn màng, thô sơ — nhưng nó đã đến, và nó vô cùng kịch tính.
Vài năm tới trong lĩnh vực AI cũng sẽ có cảm giác tương tự. Chúng ta đang ở giai đoạn giữa cuộc chơi. Năm 2023 đã là một sự chuyển dịch hoang dại. AGI từ một chủ đề ngoài lề đã trở thành chủ đề của các buổi điều trần lớn tại Thượng viện và các hội nghị thượng đỉnh của các nhà lãnh đạo thế giới. Thêm vài lần "2023" nữa, và cánh cửa Overton sẽ bị thổi bay hoàn toàn.
Khi chúng ta chạy đua qua các OOM, các bước nhảy vọt sẽ tiếp tục. Đến khoảng năm 2025/2026, tôi kỳ vọng những bước thay đổi thực sự gây sốc tiếp theo. Nếu điều đó vẫn chưa đủ, đến năm 2027/28, chúng ta sẽ có các mô hình được huấn luyện trên cụm máy chủ trị giá hơn 100 tỷ đô la; các tác nhân AI thực thụ sẽ bắt đầu tự động hóa rộng rãi kỹ thuật phần mềm và các công việc nhận thức khác. Mỗi năm, sự gia tốc sẽ khiến chúng ta cảm thấy chóng mặt.
Khi các OOM chuyển từ ngoại suy lý thuyết sang thực tế thực nghiệm, dần dần, một sự đồng thuận cũng sẽ hình thành trong số các nhà khoa học, giám đốc điều hành và quan chức chính phủ hàng đầu: chúng ta đang ở ngưỡng cửa, ngưỡng cửa của AGI, ngưỡng cửa của sự bùng nổ trí tuệ, ngưỡng cửa của siêu trí tuệ. Và đâu đó trên hành trình này, chúng ta sẽ thấy những minh chứng đầu tiên thực sự đáng sợ của AI. Rõ ràng là: dù muốn hay không, đây sẽ là một công nghệ quân sự mang tính quyết định tuyệt đối. Có lẽ sự phát hiện (không thể tránh khỏi) về việc ĐCSTQ thâm nhập vào các phòng thí nghiệm AI hàng đầu của Mỹ sẽ gây ra một chấn động lớn.
Đâu đó vào khoảng năm 26/27, bầu không khí ở Washington sẽ trở nên u ám. Mọi người sẽ bắt đầu cảm nhận một cách trực quan những gì đang xảy ra; họ sẽ sợ hãi. Từ các hành lang của Lầu Năm Góc đến các buổi họp kín của Quốc hội sẽ vang lên câu hỏi hiển nhiên: chúng ta có cần một Dự án Manhattan cho AGI không? Đầu tiên là chậm rãi, rồi sau đó là dồn dập, mọi thứ sẽ trở nên rõ ràng: điều này đang xảy ra, đây là thách thức quan trọng nhất đối với an ninh quốc gia Hoa Kỳ kể từ khi phát minh ra bom nguyên tử. Bằng hình thức này hay hình thức khác, nhà nước an ninh quốc gia sẽ tham gia rất sâu. Dự án (The Project) sẽ là phản ứng cần thiết, và thực sự là duy nhất khả thi.
Tôi không hề có ảo tưởng về chính phủ. Nhưng cuối cùng, các phòng thí nghiệm AI vẫn chỉ là các công ty khởi nghiệp. Chúng ta đơn giản không nên mong đợi các công ty khởi nghiệp có đủ khả năng để xử lý siêu trí tuệ. Không có lựa chọn tốt ở đây — nhưng tôi không thấy con đường nào khác. Khi một công nghệ trở nên quan trọng như thế này đối với an ninh quốc gia, chúng ta sẽ cần đến Chính phủ Mỹ.
SIÊU TRÍ TUỆ SẼ LÀ DỰ ÁN QUỐC PHÒNG QUAN TRỌNG NHẤT CỦA HOA KỲ
Đến đầu những năm 2030, toàn bộ kho vũ khí của Mỹ (dù bạn muốn hay không, vẫn là nền tảng của hòa bình và an ninh toàn cầu) có lẽ sẽ trở nên lỗi thời. Nó sẽ không chỉ là vấn đề hiện đại hóa, mà là một sự thay thế toàn diện. Nói đơn giản, sự phát triển AGI sẽ rơi vào danh mục giống vũ khí hạt nhân hơn là internet. Các ứng dụng dân dụng sẽ có thời của chúng. Nhưng trong làn sương mờ của giai đoạn cuối cuộc đua AGI, dù tốt hay xấu, an ninh quốc gia sẽ là bối cảnh chính.
Cho dù trên danh nghĩa là tư nhân hay không, dự án AGI sẽ cần phải là, và sẽ là, một dự án quốc phòng cốt lõi, và nó sẽ đòi hỏi sự hợp tác cực kỳ chặt chẽ với nhà nước an ninh quốc gia.
MỘT CHUỖI MỆNH LỆNH TỈNH TÁO CHO SIÊU TRÍ TUỆ
Sức mạnh — và các thách thức — của siêu trí tuệ sẽ thuộc về một nhóm tham chiếu rất khác so với bất cứ điều gì chúng ta quen thấy từ các công ty công nghệ. Rõ ràng là: điều này không nên nằm dưới quyền chỉ huy đơn phương của một CEO ngẫu nhiên. Chúng ta sẽ cần một chuỗi mệnh lệnh tỉnh táo — cùng với tất cả các quy trình và rào chắn khác vốn đi kèm với việc sử dụng có trách nhiệm một thứ tương đương với vũ khí hủy diệt hàng loạt. Chỉ có một chuỗi mệnh lệnh và tập hợp các thể chế đã chứng minh được khả năng thực hiện nhiệm vụ này (như quân đội và các cơ quan chính phủ dưới sự giám sát của Hiến pháp và pháp luật).
AN NINH
Như đã thảo luận, nếu chúng ta đối mặt với toàn bộ sức mạnh gián điệp của Trung Quốc, một công ty tư nhân có lẽ không thể có được mức độ an ninh đủ tốt. Điều đó sẽ đòi hỏi sự hợp tác sâu rộng với cộng đồng tình báo Mỹ. Điều này sẽ bao gồm các hạn chế xâm nhập đối với các phòng thí nghiệm AI và đội ngũ nghiên cứu cốt lõi, từ kiểm tra an ninh gắt gao, giám sát liên tục đến việc làm việc trong các cơ sở SCIF; và nó sẽ đòi hỏi cơ sở hạ tầng mà chỉ chính phủ mới có thể cung cấp, bao gồm cả an ninh vật lý cho các trung tâm dữ liệu AGI.
AN TOÀN
Về cốt lõi, các phòng thí nghiệm là những công ty khởi nghiệp, với tất cả các động cơ thương mại thông thường. Sự cạnh tranh có thể đẩy tất cả họ vào việc chạy đua qua cuộc bùng nổ trí tuệ mà bỏ qua an toàn. Chúng ta có thể cần "chi tiêu một phần lợi thế dẫn đầu" để có thời gian giải quyết các thách thức an toàn, nhưng các phòng thí nghiệm phương Tây sẽ cần phối hợp để làm điều đó. Chúng ta sẽ cần một chuỗi mệnh lệnh có thể mang lại sự nghiêm túc cần thiết để thực hiện những sự đánh đổi khó khăn này.
Cuối cùng, khẳng định chính của tôi ở đây mang tính mô tả: dù chúng ta có thích hay không, siêu trí tuệ sẽ không giống như một công ty khởi nghiệp ở San Francisco, mà sẽ chủ yếu nằm trong phạm vi an ninh quốc gia. Nếu một phòng thí nghiệm phát triển được siêu trí tuệ thực thụ vào ngày mai, dĩ nhiên các cơ quan liên bang sẽ can thiệp.
Một biến số quan trọng không phải là liệu có mà là khi nào. Nếu dự án của chính phủ là tất yếu, thì can thiệp sớm có vẻ tốt hơn. Chúng ta sẽ rất cần vài năm đó để thực hiện chương trình an ninh khẩn cấp, để các quan chức then chốt bắt nhịp và chuẩn bị, để xây dựng một phòng thí nghiệm hợp nhất hoạt động hiệu quả. Sẽ hỗn loạn hơn nhiều nếu chính phủ chỉ can thiệp vào phút chót.
Và vì vậy, vào năm 27/28, giai đoạn cuối sẽ bắt đầu. Đến năm 28/29, cuộc bùng nổ trí tuệ sẽ diễn ra; đến năm 2030, chúng ta sẽ triệu hồi được siêu trí tuệ, với tất cả sức mạnh và quyền năng của nó.
Bất cứ ai được giao phụ trách Dự án sẽ có một nhiệm vụ cực kỳ khó khăn: xây dựng AGI, và xây dựng nó thật nhanh; đưa nền kinh tế Mỹ vào trạng thái thời chiến để sản xuất hàng trăm triệu GPU; khóa chặt tất cả, loại bỏ các điệp viên và chống lại các cuộc tấn công tổng lực của ĐCSTQ; bằng cách nào đó quản lý được một trăm triệu AGI đang miệt mài tự động hóa nghiên cứu AI; làm sao để giữ mọi thứ không đi chệch hướng và tạo ra một siêu trí tuệ nổi loạn cố gắng giành quyền kiểm soát; sử dụng các siêu trí tuệ đó để phát triển bất kỳ công nghệ mới nào cần thiết để ổn định tình hình; tất cả trong khi lèo lái tình hình quốc tế căng thẳng nhất từng thấy. Tốt hơn hết là họ nên làm giỏi việc đó.
Đối với những người trong chúng ta nhận được cuộc gọi để tham gia hành trình này, nó sẽ... rất căng thẳng. Nhưng đó sẽ là nghĩa vụ của chúng ta để phục vụ thế giới tự do — và toàn thể nhân loại.
Hẹn gặp lại các bạn tại sa mạc, những người bạn của tôi.
Điều gì sẽ xảy ra nếu chúng ta đúng?
Trong bài này:
“Tôi nhớ ngày xuân năm 1941 cho đến tận bây giờ. Lúc đó tôi nhận ra rằng một quả bom hạt nhân không chỉ là có thể — mà là không thể tránh khỏi. Sớm muộn gì những ý tưởng này cũng sẽ không còn là riêng biệt đối với chúng tôi. Mọi người sẽ nghĩ về chúng trong một thời gian ngắn nữa, và một quốc gia nào đó sẽ đưa chúng vào hành động. […]
Và không có ai để nói về chuyện đó, tôi đã có nhiều đêm mất ngủ. Nhưng tôi đã nhận ra nó có thể nghiêm trọng đến mức nào. Và sau đó tôi đã phải bắt đầu uống thuốc ngủ. Đó là phương thuốc duy nhất, tôi chưa bao giờ dừng lại kể từ đó. Đã 28 năm rồi, và tôi không nghĩ mình đã bỏ lỡ một đêm nào trong suốt 28 năm đó.”
James Chadwick (Giải Nobel Vật lý và tác giả của báo cáo chính phủ Anh năm 1941 về tính tất yếu của bom nguyên tử, điều cuối cùng đã thúc đẩy Dự án Manhattan đi vào hành động)
Trước khi thập kỷ này kết thúc, chúng ta sẽ xây dựng xong siêu trí tuệ. Đó là nội dung chính của loạt bài này. Đối với hầu hết những người tôi trò chuyện ở San Francisco, đó là lúc màn hình tắt ngóm (mọi thứ trở nên mờ mịt). Nhưng thập kỷ tiếp theo — những năm 2030 — sẽ ít nhất cũng đầy biến động như vậy. Đến cuối thập kỷ đó, thế giới sẽ bị biến đổi hoàn toàn, không thể nhận ra được nữa. Một trật tự thế giới mới sẽ được rèn giũa. Nhưng than ôi — đó là câu chuyện cho một lúc khác.
Chúng ta phải kết thúc ở đây, vào lúc này. Hãy để tôi đưa ra một vài nhận xét cuối cùng.
Tất cả những điều này là quá nhiều để chiêm nghiệm — và nhiều người không thể làm vậy. "Học sâu đang chạm tường!" họ tuyên bố, năm này qua năm khác. "Đó chỉ là một bong bóng công nghệ khác thôi," các chuyên gia tự tin nói. Nhưng ngay cả trong số những người ở tâm điểm San Francisco, cuộc tranh luận đã bị phân cực giữa hai tiếng gọi cổ vũ cơ bản là thiếu nghiêm túc.
Ở một đầu là những người dự báo tận thế (doomers). Họ đã bị ám ảnh bởi AGI trong nhiều năm; tôi đánh giá cao sự tiên liệu của họ. Nhưng tư duy của họ đã trở nên xơ cứng, tách rời khỏi thực tế thực nghiệm của học sâu, những đề xuất của họ ngây thơ và không khả thi, và họ thất bại trong việc đối mặt với mối đe dọa độc tài rất thực tế. Những tuyên bố điên cuồng về xác suất diệt vong 99%, những lời kêu gọi tạm dừng AI vô thời hạn — đó rõ ràng không phải là con đường đúng đắn.
Ở đầu kia là những người theo chủ nghĩa gia tốc (e/accs). Xét hẹp, họ có một vài điểm đúng: tiến bộ AI phải được tiếp tục. Nhưng đằng sau những bài đăng mạng xã hội hời hợt của họ, họ là một sự giả dối; những kẻ tài tử chỉ muốn xây dựng các ứng dụng "wrapper" cho công ty khởi nghiệp của mình thay vì nhìn thẳng vào mặt AGI. Họ tuyên bố là những người bảo vệ nhiệt thành cho tự do của nước Mỹ, nhưng không thể cưỡng lại tiếng gọi quyến rũ từ tiền bạc của những kẻ độc tài khó ưa. Thực tế, họ mới chính là những người theo chủ nghĩa trì trệ thực sự. Trong nỗ lực phủ nhận các rủi ro, họ phủ nhận cả AGI; về cơ bản, họ cho rằng tất cả những gì chúng ta có chỉ là những chatbot thú vị, vốn chắc chắn không nguy hiểm. (Đó là một kiểu chủ nghĩa gia tốc kém cỏi theo quan điểm của tôi.)
Nhưng theo cách tôi thấy, những người thông minh nhất trong lĩnh vực này đã hội tụ về một quan điểm khác, một con đường thứ ba, cái mà tôi sẽ gọi là Chủ nghĩa hiện thực AGI (AGI Realism). Các nguyên tắc cốt lõi rất đơn giản:
Khi sự gia tốc tăng cường, tôi chỉ kỳ vọng cuộc tranh luận sẽ càng trở nên chói tai hơn. Nhưng hy vọng lớn nhất của tôi là sẽ có những người cảm nhận được sức nặng của những gì đang đến, và coi đó như một lời kêu gọi trang nghiêm đối với nghĩa vụ.
Đến thời điểm này, bạn có thể nghĩ rằng tôi và tất cả những người khác ở San Francisco đều hoàn toàn điên rồ. Nhưng hãy cân nhắc, chỉ một khoảnh khắc thôi: điều gì sẽ xảy ra nếu họ đúng? Đây là những người đã phát minh và xây dựng công nghệ này; họ nghĩ rằng AGI sẽ được phát triển trong thập kỷ này; và mặc dù có một phổ khá rộng, nhiều người trong số họ coi rất nghiêm túc khả năng con đường dẫn đến siêu trí tuệ sẽ diễn ra như tôi đã mô tả trong loạt bài này.
Gần như chắc chắn tôi đã sai ở những phần quan trọng của câu chuyện; nếu thực tế diễn ra gần mức độ điên rồ này, các lề sai số sẽ rất lớn. Hơn nữa, như tôi đã nói ngay từ đầu, tôi nghĩ có một phạm vi rộng các khả năng. Nhưng tôi nghĩ điều quan trọng là phải cụ thể. Và trong loạt bài này, tôi đã trình bày những gì tôi tin hiện nay là kịch bản khả thi nhất cho phần còn lại của thập kỷ này — phần còn lại của thập kỷ này.
Bởi vì — nó bắt đầu có cảm giác thật, rất thật. Vài năm trước, ít nhất là đối với tôi, tôi đã coi những ý tưởng này là nghiêm túc — nhưng chúng còn trừu tượng, bị cô lập trong các mô hình và ước tính xác suất. Giờ đây, nó mang lại cảm giác cực kỳ trực quan. Tôi có thể thấy nó. Tôi có thể thấy cách AGI sẽ được xây dựng. Nó không còn là về các ước tính kích thước não người và các giả thuyết hay ngoại suy lý thuyết nữa — tôi về cơ bản có thể nói cho bạn biết cụm máy chủ mà AGI sẽ được huấn luyện và khi nào nó sẽ được xây dựng, sự kết hợp thô của các thuật toán chúng ta sẽ sử dụng, những vấn đề chưa giải quyết và con đường để giải quyết chúng, danh sách những người sẽ đóng vai trò quan trọng. Tôi có thể thấy nó. Nó cực kỳ trực quan.
Nhưng nhận thức đáng sợ nhất là không có đội ngũ đặc nhiệm nào sắp đến để xử lý việc này. Khi còn nhỏ, bạn có cái nhìn tôn vinh về thế giới, rằng khi mọi thứ trở nên thực tế, sẽ có những nhà khoa học anh hùng, những quân nhân cực kỳ năng nổ, những nhà lãnh đạo bình tĩnh, những người sẽ giải cứu thế giới. Thực tế không phải vậy. Thế giới vô cùng nhỏ bé; khi lớp vỏ bọc bên ngoài bị lột bỏ, thường chỉ có vài người đứng sau hậu trường là những người thực sự hành động, những người đang tuyệt vọng cố gắng giữ cho mọi thứ không bị tan vỡ.
Hiện tại, có lẽ chỉ có vài trăm người trên thế giới nhận ra những gì sắp ập đến với chúng ta, những người hiểu mọi thứ sắp trở nên điên rồ đến mức nào, những người có nhận thức tình huống. Tôi có lẽ biết cá nhân hoặc chỉ cách một bậc kết nối với tất cả những người có khả năng điều hành Dự án. Một vài người đứng sau hậu trường đang tuyệt vọng cố gắng giữ cho mọi thứ không bị tan vỡ chính là bạn, những người bạn của bạn và bạn của họ. Chỉ có vậy thôi. Đó là tất cả những gì có.
Một ngày nào đó, mọi chuyện sẽ nằm ngoài tầm tay của chúng ta. Nhưng hiện tại, ít nhất là trong vài năm tới của giai đoạn giữa cuộc chơi, số phận của thế giới nằm trên vai những người này.
Liệu thế giới tự do có thắng thế?
Liệu chúng ta sẽ thuần hóa được siêu trí tuệ, hay nó sẽ thuần hóa chúng ta?
Liệu nhân loại có một lần nữa tránh được sự tự hủy diệt?
Rủi ro không hề nhỏ hơn thế.
Đây là những con người tuyệt vời và đáng kính. Nhưng họ cũng chỉ là con người. Sớm thôi, các AI sẽ vận hành thế giới, nhưng chúng ta đang chuẩn bị cho cuộc đua cuối cùng của mình. Mong rằng sự quản lý cuối cùng của họ sẽ mang lại vinh quang cho nhân loại.
Lời cảm ơn (Acknowledgments)
Cảm ơn Collin Burns, Avital Balwit, Carl Shulman, Jan Leike, Ilya Sutskever, Holden Karnofsky, Sholto Douglas, James Bradbury, Dwarkesh Patel và nhiều người khác vì những cuộc thảo luận mang tính định hình. Cảm ơn nhiều người bạn vì những phản hồi về các bản thảo sớm. Cảm ơn Joe Ronan vì sự trợ giúp về đồ họa, và Nick Whitaker vì sự trợ giúp xuất bản.
Lời đề tặng (Dedication)
Dành tặng Ilya Sutskever.
Chào bạn, tôi là Leopold Aschenbrenner.
Gần đây tôi đã thành lập một công ty đầu tư tập trung vào AGI, với các nhà đầu tư chủ chốt bao gồm Patrick Collison, John Collison, Nat Friedman và Daniel Gross. Trước đó, tôi đã làm việc tại đội ngũ Siêu căn chỉnh (Superalignment) tại OpenAI.
Trước đây, tôi đã thực hiện nghiên cứu về tăng trưởng kinh tế dài hạn tại Viện Ưu tiên Toàn cầu (Global Priorities Institute) của Đại học Oxford. Tôi vốn đến từ Đức và hiện đang sinh sống tại thành phố San Francisco tuyệt vời, bang California.
Bạn có thể tìm thấy blog cá nhân của tôi tại đây. Hoặc theo dõi tôi trên Twitter.
Bạn có thể gửi email cho tôi tại đây.
| Tiếng Anh | Tiếng Việt | Ghi chú |
|---|---|---|
| Situational Awareness | Nhận thức tình huống | |
| AGI (Artificial General Intelligence) | Trí tuệ nhân tạo tổng quát | |
| Superintelligence | Siêu trí tuệ | |
| OOMs (Orders of Magnitude) | Các bậc quy mô | Thường dùng trong tính toán (10x) |
| Compute | Điện toán / Năng lực tính toán | |
| Algorithmic efficiency | Hiệu quả thuật toán | |
| Unhobbling | Giải phóng tiềm năng / Tháo gỡ rào cản | |
| Intelligence Explosion | Sự bùng nổ trí tuệ | |
| Techno-capital acceleration | Gia tốc kỹ thuật - tư bản | |
| Labs | Các phòng thí nghiệm AI | |
| Superalignment | Siêu căn chỉnh | |
| The Project | Dự án | Ám chỉ dự án cấp quốc gia như Manhattan |
| Decisive advantage | Lợi thế quyết định | |
| CCP (Chinese Communist Party) | ĐCSTQ | |
| Weights | Trọng số | Trọng số mô hình AI |
| Data center | Trung tâm dữ liệu | |
| Cluster | Cụm máy chủ |